클러스터링 테이블
태그 :
- 개념
- - 어떤 정해진 컬럼 값을 기준으로 동일한 값을 가진 하나 이상의 테이블의 로우를 같은 장소에 저장하는 물리적인 기법.
1. 데이터 엑세스 성능 향상, 클러스터링 테이블
가. 클러스터링 테이블 정의
- 어떤 정해진 컬럼 값을 기준으로 동일한 값을 가진 하나 이상의 테이블의 로우를 같은 장소에 저장하는 물리적인 기법.
나. 클러스터링 테이블 필요성
- 기존 방식에서 많은 양의 랜덤 엑세스 발생으로 인한 오버헤드
- 처리할 데이터 영역이 광범위하면 전체 테이블을 읽어야 한다.
2.클러스터링 테이블 유형
가. 단일 테이블 클러스터링 : 넒은 범위의 데이터를 동시에 액세스하고자 할때 주로 사용
|
|
|
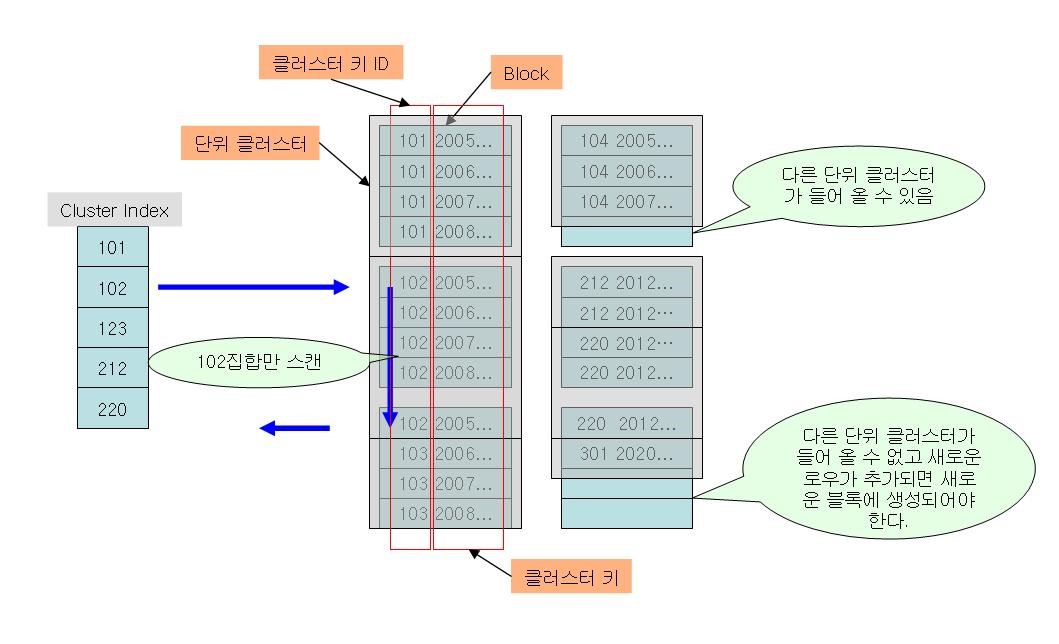
위 그림은 하나의 블럭에 최대 2개의 단위 클러스터만 존재할 수 있도록 크기(SIZE)를 지정 한 것으로 가정 했을 경우. 위 그림에서 클러스터 키는 모두 로우에 가지고 있는것으로 표현되어있지만 실제로는 블럭헤더에 클러스터키ID와 클러스터키를 가지고 있다.(클러스터키가 되는 컬럼값은 한번만 저장됨을 의미) 만약 어떤 로우에 클러스터키가 되는 컬럼값이 수정된다면 수정된 값에 맞는 단위클러스터로 이동해야 하는데 이럴 경우 ROWID는 새로 이주해 가야할 곳의 ROWID를 남겨두고 현재 ROWID정보를 가지고있는체 이동하게 된다. 일반 인덱스 스캔에 5~8배 향상 기대 좁은 분포도에서는 같은 단위 클러스터에 속한 로우 수가 적어짐을 의미 일반 인덱스를 사용한 것보다 효과가 떨어질 수 있음 지정된 위치에 저장되어야 하기 때문에 검색을 제외한 모든 경우 부하가 발생 |
나. 다중 테이블 클러스터링 : 단위 클러스터에 두개 이상의 테이블을 함께 저장하는것
|
|
|
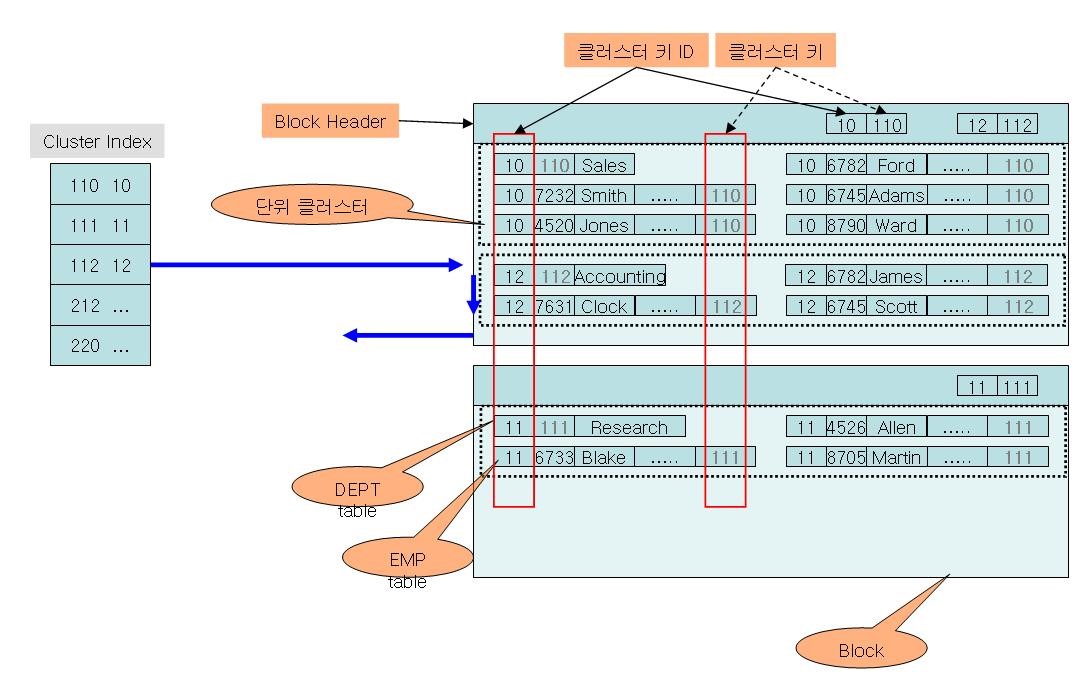
위 그림에서 클러스터키 컬럼 DEPTNO이다 각 로우는 클러스터키ID를 가지고 있고 블럭헤더에는 클러스터키ID와 클러스터키 정보를 가지고 있다. 따라서 단위클러스터 안에서는 클러스터키 값을 가지고 있을 필요가 없고(회색으로 표시된 값들이 이에 해당함) 실제로 저장되지 않는다. 정규화작업으로 분할된 테이블들을 마치 하나의 테이블처럼 액세스할 수 있다. 제 1정규화작업에 의해서 한테이블에서 별개의 테이블로 분할 된 테이블은 정규화작업 이전에 한레코드에 있어서 액세스 할 수 있었으나 분할 된 후 일일이 키 값을 가지고 조인을 통해 하는 부담이 있고 서로 테이블의 로우가 주변에 모여있다고 확신 할 수도 없다. 이러한 경우 다중 테이블 클러스터링으로 몇 가지 불만이 해소된다. 클러스터링된 테이블간의 연결도 중요하지만 수많은 다른 테이블들과의 관계를 맺고자 하는 경우. |
다. 해시 값을 이용한 클러스터 테이블 : 클러스터링이라기 보다 일종의 인덱스를 대신
|
|
|
|
개념 |
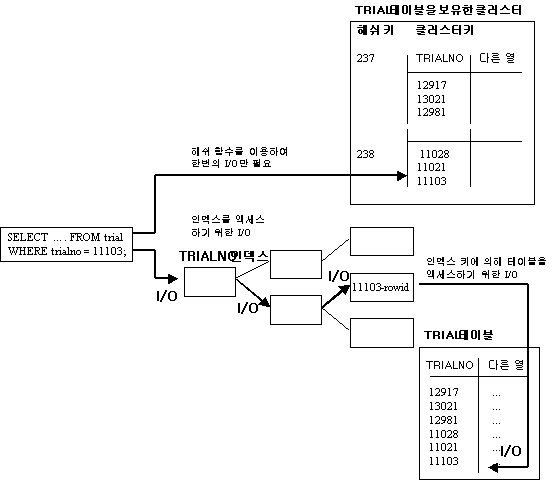
클러스터링이라기 보다 일종의 인덱스를 대신하는 개념 해쉬값을 이용해 테이블의 데이타를 정해진 위치에 저장하고(클러스터링개념) 우리가 원하는 값을 찾아간다(인덱스개념) 아주 특정한 경우에 한정되어 사용됨 |
|
특징 |
SIZE, HASHKEYS, HASH IS 파라미터는 변경 할 수 없다. '='로만 액세스해야 한다. 클러스터가 생성되면서 저장공간이 미리 할당된다. 지정된 단위 클러스터 보다 많은 로우가 들어오면 OVERFLOW영역에 저장된다. 컬럼의 값이 고르게 분포되어 있지 않으면 해쉬키 값의 충돌(COLLISION)이 발생한다. 인덱스를 경유하지 않고 해쉬 함수로 계산된 값으로 직접 테이블 액세스하므로 인덱스보다 효율적인 액세스를 할 수 있다. |
|
활용범위 |
사전에 해쉬키의 개수와 저장공간을 확보해야 하기때문에 지속적으로 대량의 데이타가 증가하는 테이블에는 적용하지 않는 것이 좋다. 내용적으로 항상 '='을 사용하는 경우만 사용 가능 클러스터키 컬럼의 균등한 분포에 적당 대량의 데이터를 해쉬 클러스터에 저장시키고자 한다면 해쉬 파티션을 사용하는 것이 옳다. |
|
해시 클러스터의 정의 |
CREATE CLUSTER[schema.] cluster (column datatype[,column datatype]...) HASHKEYS integer [HASH IS expression] [PCTFREE interger] {PCTUSED integer} [INITRANS interger] [MAXTRANS integer] [SIZE interger[K|M]] [storage_clasue] [TABLESPACE tablespace] |
|
구성요소 |
HASHKEYS 해쉬 클러스터를 작성하기 위해 명시 명시하지 않으면 인덱스 클러스터가 기본 값으로 생성 해쉬 키 값의 개수를 지정 소수가 아닐 경우 다음으로 높은 소수로 결정(예 : 100이면 101선택) 최소 값 : 2 HASH IS 해쉬 값으로 사용할 컬럼을 지정 클러스터 키는 NUMBER 데이타 타입의 단일 컬럼이어야 함 해쉬 함수를 적용한 결과는 양수이어야 함 사용자 정의 해쉬 함수 사용 가능, 생략시 시스템 내부 함수 사용 SIZE 데이타 블록에 할당될 해쉬 키의 수 지정 해쉬 키에 대해 모든 행들을 저장하기 위해 필요한 평균 공간 설정 해쉬 클러스터가 단일 테이블로 구성되고 키 값에 대해 하나의 행만 가지면 SIZE 파라미터는 테이블의 평균 행 크기로 설정 해쉬 클러스터가 단일 테이블로 구성되고 키 값에 대해 여러 개의 행을 가지면 SIZE 파라미터는 키 값에 대해 행의 수를 곱한 크기로 설정 해쉬 클러스터가 복수 개의 테이블로 구성되면 SIZE 파라미터는 해쉬 값과 연관있는 모든 행을 포함하기 위한 평균 공간으로 설정 지나치게 크게 설정하면 낭비되는 공간 증가 |
3. 클러스터링 테이블 비용
가. 클러스터링 테이블 비용
액세스 형태를 모두 수집, 분석하여 적은 비용이 드는 인덱스로 해결하도록 노력
나. 입력시의 부하
- 클러스터키 값에 따라 저장 위치가 달라짐
- 키 값이 다를 경우 여러개의 블록에 따로 저장될 수 있음
- 일반 테이블의 경우, 값이 다르더라도 같은 블록에 한꺼번에 저장되는 것과 비교됨
- 일반 테이블이라도 여러개의 인덱스가 존재할 경우 위치 선정에 따른 부하가 발생
- 클러스터링 도입으로 인덱스의 개수가 줄어든다면 부하 증가의 염려를 줄일 수 있음
다. 수정시의 부하
- 클러스터키 컬럼 값의 수정시 row migration 발생하여 clustering factor 저하
- 클러스터키 컬럼이 아닌 데이터의 수정은 일반 테이블의 수정과 동일하여 추가적인 부하가 없음
- 수정이 빈번한 컬럼을 클러스터키 컬럼으로 지정하지 않도록 할 것
라. 삭제시의 부하
- 클러스터링 테이블의 모든 row를 삭제하더라도 인덱스는 그대로 존재함
- 테이블 drop의 경우 row를 제거하는 것이지 단위 클러스터를 제거하는 것이 아님 따라서, delete를 수행하게 되어 많은 부하가 발생하게 됨
- 새로운 클러스터에 데이터를 생성하고 rename하는 방법이 바람직함
4. 클러스터 테이블 생성 예시
가. 클러스터 생성
SQL> Create cluster cluster_test(testkey number(3))
Size 400
Tablespace users
Storage(initial 30k);
나.클러스터 인덱스 생성
SQL > create index index_cluster
On cluster cluster_test
Tablespace users;
다. 클러스터할 테이블 생성
SQL> Create table clustable(
Name varchare(10),
Hire_date date,
Testkey number(3))
Cluster cluster_test(testkey);