연관분석
태그 :
- 개념
- - 특정 사건(상품 구매)들이 동시에 발생하는 빈도로 상호간의 연관성을 지지도, 신뢰도, 향상도로 측정하는 분석 기법
Ⅰ. 두 제품 또는 사건 사이의 연관성의 발견, 연관규칙(Association Rule)의 개요
가. 데이터 마이닝의 연관규칙의 정의
- 특정 사건(상품 구매)들이 동시에 발생하는 빈도로 상호간의 연관성을 지지도, 신뢰도, 향상도로 측정하는 분석 기법
나. 데이터 마이닝의 연관규칙의 특징
- 대용량 데이터베이스 내의 단위 트랜잭션에서 빈번하게 발생하는 사건의 유형을 발견
- 동시에 구매될 가능성이 큰 상품들을 찾아냄으로써 장바구니 분석(Market Basket Analysis)에서 다루는 문제들에 적용 가능
- 활용분야
1) 진열대에 상품을 어떻게 배치할 것인가
2) 카탈로그를 어떻게 구성하면 매출을 늘릴 수 있을까
3) 패키지 상품은 어떻게 구성할 것인가
Ⅱ. 연관 규칙의 개념도 및 연관 규칙 발견 과정
가. 연관 규칙의 개념도

- 연관규칙: “상품 A가 구매된 경우는 상품 B도 구매된다.”
나. 연관 규칙 발견 과정
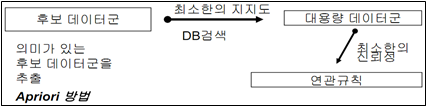
- 대용량 데이터군 검색: 트랜잭션을 대상으로 최소지지도 이상을 만족하는 빈발항목 집합을 발견하는 과정
- 연관규칙 발견: 발견된 다량 항목 집합 내에 포함된 항목들 중에서 최소신뢰도 이상을 만족하는 항목들 간의 연관규칙을 생성하는 단계
Ⅲ. 연관규칙의 정량화 기준 및 장단점
가. 연관 정도를 정량화 하기 위한 세 가지 기준
|
구분 |
설명 |
|
지지도(Support) |
전체 거래 중 항목 X와 항목 Y를 동시에 포함하는 거래의 정도를 나타내며 전체 구매도에 대한 경향 파악 |
|
|
|
|
신뢰도(Confidence) |
항목 X를 포함하는 거래 중에서 항목 Y가 포함될 확률이 어느 정도인가를 나타내며 연관성의 정도를 파악 |
|
|
|
|
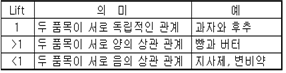
향상도 (Lift / Improvement) |
항목 X를 구매한 경우 그 거래가 항목 Y를 포함하는 경우와 항목 Y가 임의로 구매되는 경우의 비 |
|
|

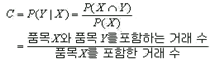
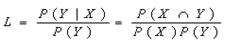
나. 연관규칙의 장단점
|
구분 |
설명 |
|
장점 |
- 탐색적 기법 : 조건 반응(if-then)으로 표현되는 연관성분석의 결과 이해가 쉬움 - 강력한 비목적성 분석기법 : 분석방향이나 목적이 특별히 없는 경우 목적변수가 없으므로 유용함 - 사용 편리한 분석데이터의 형태 : 거래내용에 대한 데이터를 변환 없이 그 자체로 이용할 수 있는 간단한 자료구조를 갖는 분석방법 - 계산의 용이성 : 분석을 위한 계산이 비교적 간단 |
|
단점 |
- 많은 계산과정 : 품목수가 증가하면 분석에 필요한 계산은 기하급수적으로 늘어남. - 적절품목 결정 필요 : 너무 세분화된 품목을 가지고 연관성 규칙을 찾으면 의미 없는 분석이 될 수도 있음 - 품목 간 비율차이 발생 : 거래량이 적은 품목은 포함된 거래수가 적으며, 규칙발견 시 제외되기가 쉬움 |
Ⅳ. 연관규칙 사례
가. 사례 1
|
판매 품목 |
거래 수 |
|
TV 구매 |
4,000 |
|
DVD 구매 |
2,000 |
|
TV와 DVD 동시 구매 |
1,000 |
|
전체 거래 수 |
10,000 |
- TV에 대한 DVD의 지표분석 (TV를 사면 DVD도 같이 산다.)
- 지지도(Support) : 전체 거래 중 TV와 DVD를 구매한 사람 비율
= TV & DVD / 전체거래 수 = 1,000/10,000 = 10%
- 신뢰도(Confidence) : TV를 산 사람들 중에 DVD를 산 사람들의 비율
= TV & DVD / TV = 1,000/4,000 = 25%
- 리프트(Lift) : TV를 사면 DVD도 같이 사는 경우의 비율
= 지지도/(TV구매확률*DVD구매확률)
= 0.1/(0.4*0.2) = 1.25 > 1 ∴ 연관성 있음.
나. 사례 2
- 우유 ⇒ 주스의 지지도와 신뢰도가 각각 얼마인가?
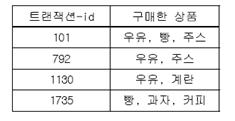
- 지지도 =(우유 + 주스 거래수)/전체거래수 = 2/4 = 50%
- 신뢰도=(우유 + 주스 거래수)/우유가 포함된 거래수 = 2/3 = 67%
- 리프트= 지지도/(우유구매확률*주스구매확률) = 0.5/(0.75*0.5) = 1.33