반정규화개요
태그 :
- 개념
- - 정규화된 엔티티 타입, 속성, 관계에 대해 시스템의 성능향상과 개발 및 운영의 단순화를 위해 데이터 모델을 통합하는 프로세스를 의미함. - 적정 수준의 정규화 이후, 질의 성능 향상을 위해, 일부의 데이터에 대해 중복을 허용하는 정규화의 역작업
1. 질의성능향상을 위한 데이터의 중복 허용, 반정규화의 개요
가. 반정규화 (Denormalization)의 정의
- 정규화된 엔티티 타입, 속성, 관계에 대해 시스템의 성능향상과 개발 및 운영의 단순화를 위해 데이터 모델을 통합하는 프로세스를 의미함.
- 적정 수준의 정규화 이후, 질의 성능 향상을 위해, 일부의 데이터에 대해 중복을 허용하는 정규화의 역작업
나. 반정규화를 고려할 때 중요 검토 기준
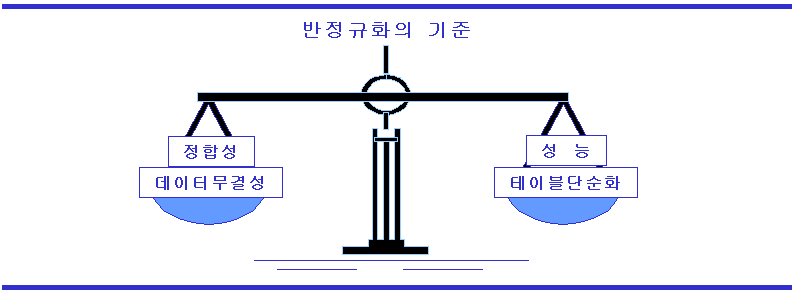
-정합성과 데이터 무결성, 성능과 테이블 단순화의 Trade off를 검토.
-정규화는 정합성과 무결성을 보장하는 대신 성능의 저하를 가져올 수 있으며, 반정규화는 성능과 모델의 단순화에 대한 이점이 있지만 무결성 저하로 시스템의 안정성을 해칠 수 있음.
다. 반정규화 이유
-데이터 조회시 디스크 I/O량이 많아서 성능 저하 발생
-경로가 너무 멀어 조인으로 인한 성능 저하
-과도한 정규화로 인한 데이터 분산화
-정상적인 정규화를 통한 고객의 품질 요구사항 충족이 어려운 경우 ( Full search )
2. 반정규화의 절차 및 유형
가. 반정규화의 절차
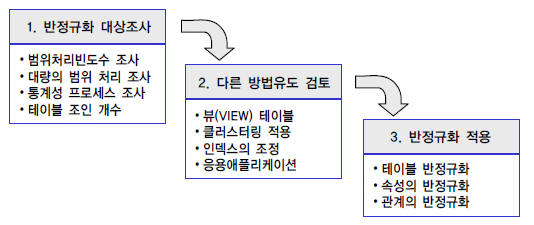
|
절 차 |
방 법 |
설 명 |
|
1. 반정규화 대상 조사 |
범위 처리 빈도수 조사 |
자주 사용되는 테이블에 접근하는 프로세스 수가 많고, 항상 일정한 범위만을 조회하는 경우 |
|
대량의 범위처리 조사 |
테이블에 대량의 데이터가 있고 대량의 데이터 범위를 자주 처리하는 경우에 처리범위를 일정하게 줄이지 않으면 성능을 보장할 수 없을 경우 |
|
|
통계성 프로세스 조사 |
통계성 프로세스에 의해 통계 정보를 필요로 할 때 별도의 통계테이블(반정규화 테이블)을 생성 |
|
|
테이블 조인 개수 조사 |
테이블에 지나치게 많은 조인(JOIN)이 걸려 데이터를 조회하는 작업이 기술적으로 어려울 경우 반정규화를 검토 |
|
|
2. 다른 방법 유도 검토 |
뷰(View) 테이블 |
지나치게 많은 조인(JOIN)이 걸려 데이터를 조회하는 작업이 기술적으로 어려울 경우 뷰(VIEW)를 사용 |
|
클러스터링 적용 |
대량의 데이터를 특정 클러스터링 팩트에 의해 저장방식을 다르게 하는 방법(조회중심의 테이블에만 적용가능) |
|
|
인덱스 적용 |
인덱스를 통해 성능을 충분히 확보할 수 있다면 인덱스를 조정하여 반정규화를 회피 |
|
|
응용 애플리케이션 |
응용 애플리케이션에서 로직을 구사하는 방법을 변경함으로써 성능을 향상 |
|
|
3. 반정규화 적용 |
- 테이블 반정규화 - 속성의 반정규화 - 관계의 반정규화 |
|
나. 반정규화 유형
|
구 분 |
반정규화 기법 |
설 명 |
|
테이블 반정규화 |
테이블 병합 |
- 조인되는 경우가 많아서 테이블을 합치는 것이 성능향상에 효율적일 경우에 적용 - 1:1 관계테이블 병합 - 1:M 관계테이블 병합 - 슈퍼/서브 타입 관계 테이블 병합 |
|
테이블 분할 |
- 테이블에서 특성 속성들만 집중적으로 접근할 경우 분할 - 접근 빈도, 잠김 현상, 경합 현상의 감소를 가져오지만 분할된 테이블의 전체 조회 시 union을 사용해야 하므로 성능이 느려짐 1) 수직 분할: 특정 속성들만 접근이 잦을 경우 칼럼을 쪼개서 테이블을 만듦.
2) 수평 분할: 스키마는 동일하지만, 그 데이터 값을 이용하는 방법이 row별로 구분 지어지는 경우 (연도별 이력 조회 등)
|
|
|
테이블 추가 |
|
|
|
칼럼 반정규화 |
중복칼럼 추가 |
|
|
파생칼럼(Derived Column) 추가 |
|
|
|
이력 테이블 칼럼 추가 |
|
|
|
PK에 의한 칼럼 추가 |
|
|
|
응용시스템 오동작을 위한 칼럼 추가 |
|
|
|
관계 반정규화 |
중복관계 추가 |
데이터를 처리하기 위한 여러 경로를 거쳐 조인이 가능하지만 이 때 발생할 수 있는 성능저하를 예방하기 위해 추가적인 관계를 맺는 방법
|
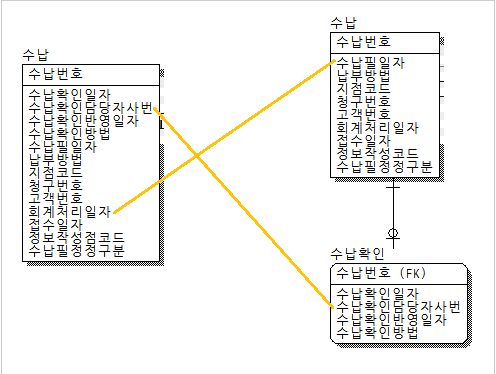
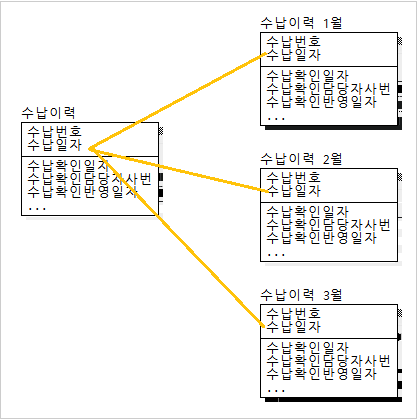
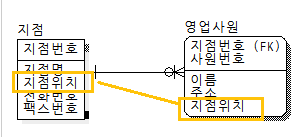
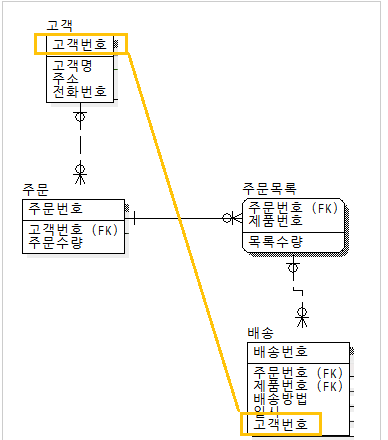
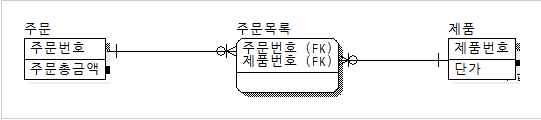
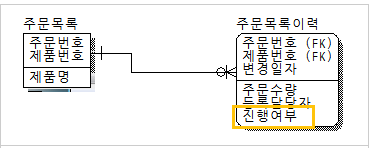

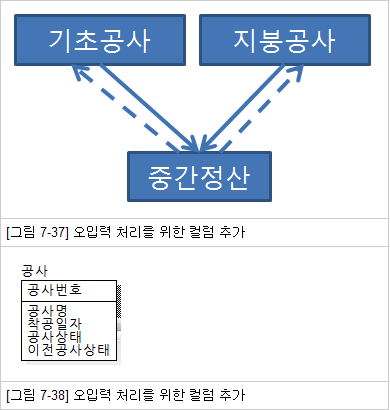
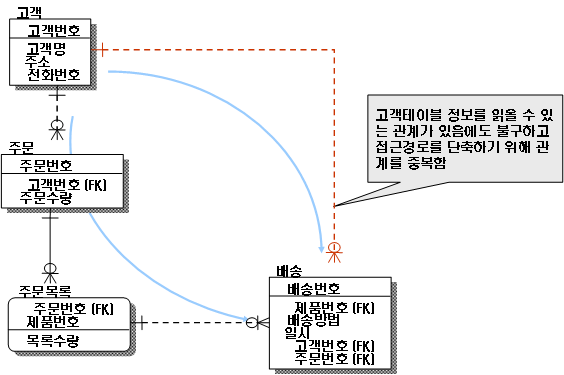
-테이블과 칼럼의 반정규화는 데이터 무결성에 영향을 미치게 되나 관계의 반정규화는 데이터 무결성을 깨뜨릴 위험을 갖지 않고서도 데이터처리의 성능을 향상시킬 수 있는 반정규화의 기법
3. 데이터 웨어하우징 시스템에서 반정규화를 도입하는 이유
|
단 계 |
내 용 |
|
비즈니스 운영성 향상 |
반정규화를 수행함으로써 중복 데이터가 발생하여 조회성능은 저하될 수 있으나 ad-hoc(임의) 쿼리를 수행하여 관리, 비즈니스 계획 및 실행을 위해 DW를 이용하는 사용자들의 만족도를 높일 수 있음 |
|
데이터 클러스터링의 사용 편의성 |
차원적 데이터 분석을 위하여 정규화를 거친 Multi-depth 데이터의 경우 Pivoting을 통한 정보 이해력이 떨어지므로, 분석을 위해서 반정규화를 실시 |
|
데이터 적시성 향상 |
ETL(Extract/Transform/Load) 개발시간 및 수행시간을 단축하여 최신 데이터 반영의 주기를 빠르게 제공 가능함. |