SQL 부분범위처리
태그 :
- 개념
- 조건을 만족하는 전체범위를 처리하는 것이 아니라 일단 운반단위(Array Size) 까지만 처리 하여 추출하는 처리방식
1. SQL 부분범위처리의 개요
가. SQL 부분처리의 정의
조건을 만족하는 전체범위를 처리하는 것이 아니라 일단 운반단위(Array Size) 까지만 처리 하여 추출하는 처리방식.
나. SQL 부분처리의 목적
스캔범위를 나누어서 운반단위를 가능한 빨리 채워서 처리속도를 향상.
일부분만 처리하고서도 Optimizer의 특성을 이용하여 정확한 결과 도출.
처리 범위가 넓더라도 빠른 속도를 얻도록 하기 위함
다. SQL 부분처리의 적용원칙
|
구분 |
설명 |
|
부분범위처리의 자격 |
논리적으로 전체범위를 읽어 추가적인 가공을 하지 않고도 동일한 결과를 추출할 수 있다면 자격이 있다.
|
|
부분범위처리를 할 수 없는 경우 |
- ORDER BY가 사용된 경우 - UNION, MINUS, INTERSECT를 사용한 경우 |
|
부분범위처리를 할 수 없는 경우의 대체 |
- ORDER BY -> INDEX를 이용하여 ORDER BY를 하지 않아도 되는 형태로 대체 - MINUS, INTERSECT -> EXISTS, NOT EXISTS, IN, NOT IN |
2. SQL 부분범위처리의 구성도 및 수행속도 향상의 원리
가. SQL 부분범위처리의 구성도 (1)

1) 전체범위처리와 부분범위처리의 차이점을 표현한 구성도 (1).
SQL 부분범위처리의 구성도 (2)
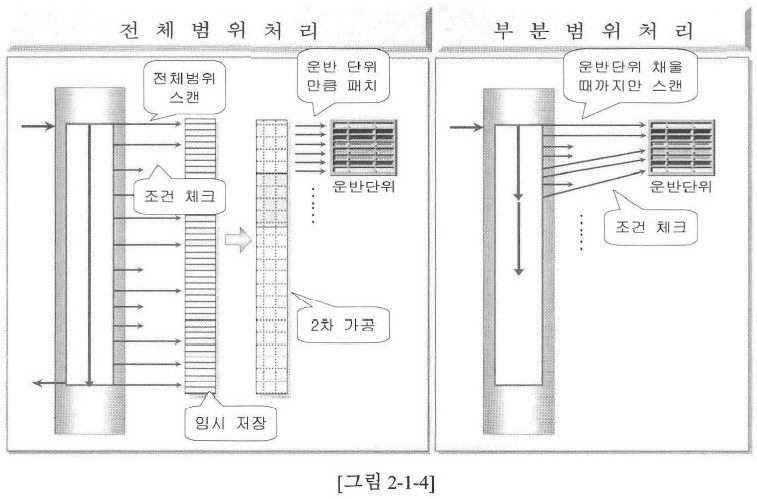
2) 전체범위처리와 부분범위처리의 차이점을 표현한 구성도 (2)
다. 부분범위처리의 수행속도 향상원리
1) 수행속도는 운반단위를 채우는 속도에 비례한다.
|
액세스주관 조건의 범위 |
검증조건의 범위 |
수행속도 |
조치사항 |
|
좁다 |
좁다 |
양호 |
|
|
좁다 |
넓다 |
양호 |
|
|
넓다 |
좁다 |
불량 |
주관조건과 검증조건의 역할을 교체 |
|
넓다 |
넓다 |
양호 |
|
3. SQL 범위처리로의 유도
|
구분 |
내용 |
|
|
인덱스나 클러스터를 이용하여 SORT를 대체 |
SQL구문에 order by가 있는 경우 인덱스등을 이용하여 order by를 빼도 되는 형태로 변환한다. |
|
|
인덱스만으로 엑세스해도 되는 구조 |
결과 컬럼을 얻어올때 인덱스에서 모두 가져올 수 있는 항목인지를 살펴서 인덱스가 다시 테이블을 읽지 않아도 되는 형태로 사용한다. |
|
|
MAX값을 얻어와야 할 경우 인덱스를 이용 |
보통 사용하는 MAX(seq)+1 형태를 버리고 역순 인덱스를 이용하여 next seq를 구하는 형태로 변경한다 |
|
|
EXISTS를 활용 |
데이터의 존재여부를 체크하는 등의 로직을 수행해야 할때 count()를 수행하는 것보다는 exists를 이용하여 존재여부를 파악한다. |
|
|
ROWNUM을 활용 |
rownum은 오라클의 pseudo column이다. 이를 이용하여 부분적으로 필요한 데이터만을 얻어올 수 있는 구조로 정의하여 사용한다.
실행순서 1). FROM/WHERE 절을 처리한다. 2). ROWNUM이 할당되고 FROM/WHERE절에서 전달되는 각각의 출력 로우에 대해 증가한다. 3). SELECT가 적용된다. 4). GROUP BY 조건이 적용된다. 5). HAVING 조건이 적용된다. 6). ORDER BY 조건이 적용된다. |
|
|
조건의 범위가 너무 넓다면 SQL을 이원화하여 처리 |
||
4. 전체범위처리와 부분범위처리 비교
|
구분 |
전체범위처리 |
부분범위처리 |
|
특징 |
주어진 조건의 범위가 좁은 경우는 문제가 없으나 넓은 경우는 빠른 수행속도를 기대하기 어려움 |
처리할 범위가 아무리 넓다고 하더라도 그 범위 중의 일부만 처리 |
|
스캔방법 |
드라이빙 조건을 만족하는 범위를 모두 스캔 |
드라이빙 조건을 만족하는 범위를 차례로 스캔함 |
|
체크조건 처리방법 |
체크조건 검증한 후 성공한 건에 대해 임시 저장공간에 저장 |
체크조건을 검증하여 성공한 건을 바로 운반단위로 보냄 |
|
결과추출방법 |
저장이 완료되면 필요한 2차 가공을 한 후 운반단위만큼 추출시키고 다음 요구가 있을 때까지 일단 멈춤 |
운반단위가 채워지면 수행을 멈추고 결과를 추출 |
|
공통점 |
항상 운반단위만 채워지면 일단은 멈춘다 |
|
|
참고 |
운반단위만큼만 추출되었다고 그것이 부분범위 처리를 한 것이라고 단정지어서는 안된다 |
|
5. 부분범위처리 예제
예제 1)
|
SELECT MAX(ORDDATE) FROM ORDER1T WHERE ORDDEPT = '430' AND STATUS = '30' (2.53초 소요)
1 SORT AGGREGATE 15230 INDEX RANGE SCAN DEPT_DATE
부서+일자로 인덱스로 잡혀 있다. 그런데 조건에 날짜가 없으므로 전체에서 15230건의 인덱스 스캔을 한 다음 소트를 하여 그 결과를 돌려 준다.
SELECT /*+ INDEX_DESC(A dept_date) */ ORDDATE FROM ORDER1T A WHERE ORDDEPT = '430' AND STATUS='30' AND ROWNUM = 1 (0.01 초 소요)
1 COUNT STOPKEY 1 TABLE ACCESS BY ROWID ORDER1T 2 INDEX RANGE SCAN DESCENDING DEPT_DATE
역순으로 인덱스를 읽으라는 힌트를 주고 1건만 읽어 온다. |
예제 2)
|
SELECT TYPE, COUNT(*) FROM ORDER2T WHERE ITEM LIKE 'HJ%' GROUP BY TYPE (10.3초 소요)
20 SORT GROUP BY 36630 TABLE ACCESS BY ROWID ORDER2T 36631 INDEX RANGE SCAN ITEM_STATUS
아이템+스테이터스로 인덱스가 잡혀 있다. 아이템 인덱스 레인지 스캔 36631건을 한 다음, ORDER2T테이블 엑세스를 36630건 한 다음 소트하여 타입별로 그룹바이해서 count값을 을 돌려 준다.
SELECT STATUS, COUNT(*) FROM ORDER2T WHERE ITEM LIKE 'HJ%' GROUP BY STATUS
(2.5초 소요)
20 SORT GROUP BY 36631 INDEX RANGE SCAN ITEM_STATUS
타입으로 order by하지 않고 인덱스에 status가 인덱스로 잡혀 있으므로 테이블 엑세스를 하지 않아도 되므로 속도가 엄청나게 향상 된다.
|
예제3)(EXISTS)
|
1. SELECT COUNT(*) INTO :CNT FROM ITEM_TAB WHERE DEPT = '101' AND SEQ > 100 . . . . . . . IF CNT > 0 . . . . . . . . . .
2. SELECT 1 INTO :CNT FROM DUAL WHERE EXISTS (SELECT 'X' FROM ITEM_TAB WHERE DEPT = '101' AND SEQ > 100 ) . . . . . . . IF CNT > 0 . . . . . . .
첫번째의 경우 해당하는 것이 1000건 10000건에 상관 없이 무조건 만족하는 것의 모두를 카운트 한다. 그러나, 두번째에서 exists를 사용하여 1건이라도 해당 하면 쿼리 실행은 중단 된다.
SELECT 1 INTO :CNT FROM ITEM_TAB WHERE DEPT = '101' AND SEQ > 100 AND ROWNUM = 1 . . . . . . . . IF CNT > 0 . . . . . . . . 마찬가지로 rownum을 활용 해서도 할 수 있다. |