장애와 회복기법
태그 :
- 개념
- 데이터회복(Data Recovery)의 정의 - 데이터베이스 운영 도중 예기치 못한 장애(Failure)가 발생할 경우 데이터베이스를 장애 발생 이전의 일관성과 무결성을 복원
1. 데이터의 일관성과 무결성을 위한 데이터회복의 개요
가. 데이터회복(Data Recovery)의 정의
- 데이터베이스 운영 도중 예기치 못한 장애(Failure)가 발생할 경우 데이터베이스를 장애 발생 이전의 일관성과 무결성을 복원.
나. 데이터 베이스 장애의 유형
|
유형 |
주요내용 |
|
트랜잭션 장애 |
- 논리적 오류 : 내부적인 오류로 트랜잭션을 완료할 수 없음. - 시스템 오류 : Deadlock 등의 오류 조건으로 활성 트랜잭션을 강제로 종료 |
|
시스템 장애 |
- 전원, 하드웨어, 소프트웨어 등의 고장 -시스템 장애로 인해 저장 내용이 영향 받지 않도록 무결성 체크 |
|
디스크 장애 |
- 디스크 스토리지의 일부 또는 전체가 붕괴되는 경우 - 가장 최근의 덤프와 로그를 이용하여 덤프 이후에 완결된 트랜잭션을 재실행(REDO) |
|
사용자 장애 |
- 사용자들의 데이터베이스에 대한 이해 부족으로 발생 - DBA 가 데이터베이스 관리를 하다가 발생시키는 실수 |
다. 데이터베이스 회복을 위한 주요 요소
|
구분 |
요소 |
개념 |
|
회복의 기본원칙(중복) |
데이터 |
- 데이터의 중복 |
|
Archive 또는 Dump |
- 다른 저장장치로 자료의 복사 및 덤프 |
|
|
Log 또는 journal |
- 데이터베이스 내용이 변경될 때마다 변경내용을 로그파일에 저장. - 갱신된 속성의 과거값/갱신값을 별도의 파일에 유지 - 온라인로그(디스크), 보관로그(테이프) |
|
|
회복을 위한 조치 |
REDO |
- 최근 변경된 내용을 로그파일에 기록하고, 장애발생시 로그파일을 읽어서 재실행함으로 데이터베이스 내용을 복원 - Archive 사본 + log : commit 후의 상태 |
|
UNDO |
- 장애발생 시 모든 변경된 내용을 취소함으로 원래의 데이터베이스 상태로 복원 - Log + Backward 취소연산 : 해당 트랜잭션 수행이전 상태 |
|
|
시스템 |
회복관리기능 |
- 신뢰성 제공을 위한 DBMS 서브시스템 |
[참고] journal : Transaction 발생 시, 생성 및 변경 Data를 Table 및 로그에 남기는 방법
2. 데이터베이스 회복 기법 유형
가. 데이터베이스 회복 기법의 종류
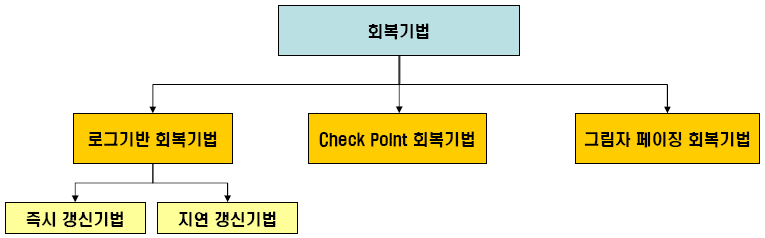
데이터베이스 회복 기법 비교
|
구분 |
로그기반 기법 |
Check Point 회복 기법 |
그림자 페이징 기법 |
|
개념 |
-로그파일을 이용한 복구 |
-로그파일과 검사점을 이용한 복구 |
-그림자 페이지 테이블을 이용한 복구 |
|
특징 |
- Redo, Undo를 결정하기 위해서 로그 전체를 조사 - 시간지연 - Redo를 할 필요가 없는 트랜잭션 또다시 Redo 발생 |
-로그기반보다 상대적으로 회복속도가 빠름 |
-Undo가 간단, Redo가 불필요 -수행속도 빠르고 간편 -여러 트랜잭션이 병행 수행되는 환경에서는 단독 사용이 어려움 -로그 기반이나 검사점 기법과 함께 사용. -그림자 페이지 테이블 복사, 기록하는데 따른 오버헤드 발생. |
|
복구과정 |
Redo, Undo 사용 |
Undo 사용 |
그림자 테이블 교체 |
|
복구속도 |
느림 |
로그보다 빠름 |
복사 및 백업본에서 복구하므로 복구 속도가 빠름 |
3. 데이터베이스 회복 기법 상세 설명
가. 지연 갱신기법(Deferred Update)
|
갱신 |
- 트랜잭션 단위가 종료될 때까지 DB에 Write 연산을 지연시키고 - 동시에 DB 변경내역을 Log 에 보관한 후 - 트랜잭션이 완료되면 Log 를 이용하여 데이터베이스에 Write 연산 수행 |
|
회복 |
- 트랜잭션이 종료된 상태이면 회복 시 Undo 없이 Redo 만 실행함. - 트랜잭션이 종료가 안된 상태였으면 Log 정보는 무시함. |
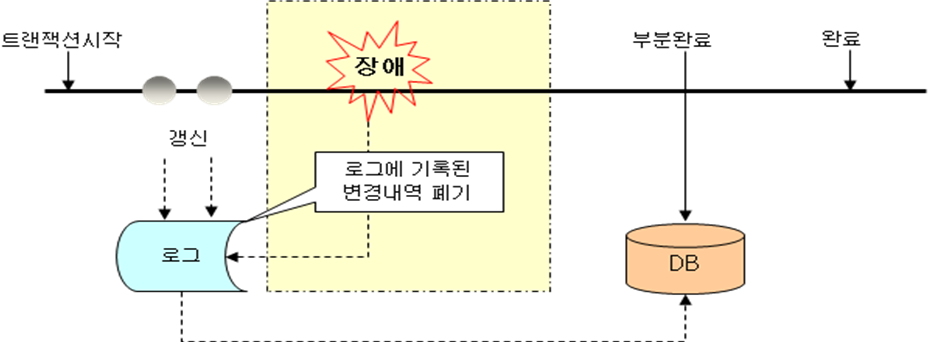

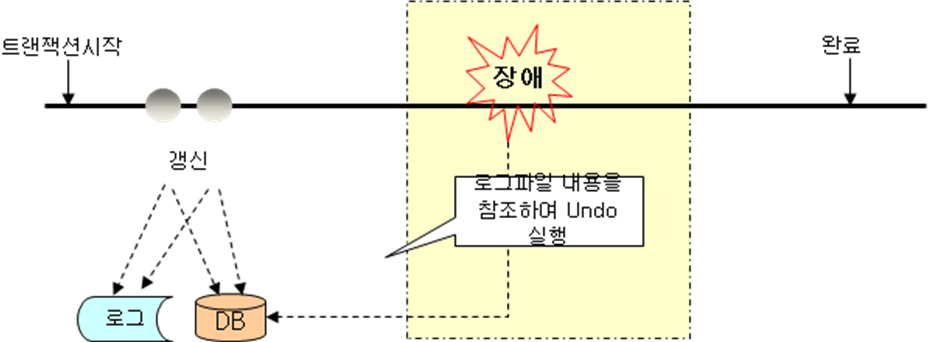
나. 즉시 갱신기법(Immediate Update)
|
갱신 |
-트랜잭션 활동상태에서 갱신결과를 DB 에 즉시 반영하고 log 기록 |
|
회복 |
-트랜잭션 수행 도중 실패상태에 도달하여 트랜잭션을 철회할 경우에는 로그 파일에 저장된 내용을 참조하여 Undo 연산 수행 |

다. Check Point 회복기법
|
갱신 |
- 검사점(Check Point)을 Log 파일에 기록하고 장애 발생시에 검사시점 이전에 처리된 트랜잭션은 회복작업에서 제외하고 검사시점 이후에 처리된 내용에 대해서만 회복작업을 수행하는 회복기법 |
|
회복 |
- 트랜잭션 수행도중 문제점이 발생하면, 로그 파일의 정보를 모두 검사하여, Redo 와 Undo 연산을 실행할 트랜잭션과 체크포인트를 선정 - 검사점의 Log 파일 기록을 이용하여 실행함. - 장애 발생시 검사점 이전에 처리된 트랜잭션들을 회복대상에서 제외 - 검사점 이후에 처리된 트랜잭션에 대해서만 회복작업을 시행함. - 새로 시작한 트랜잭션은 Undo 리스트 - Commit 된 트랜잭션은 Redo 리스트 - 로그 역방향으로 Undo 실행 후 로그 방향으로 Redo 실행 |
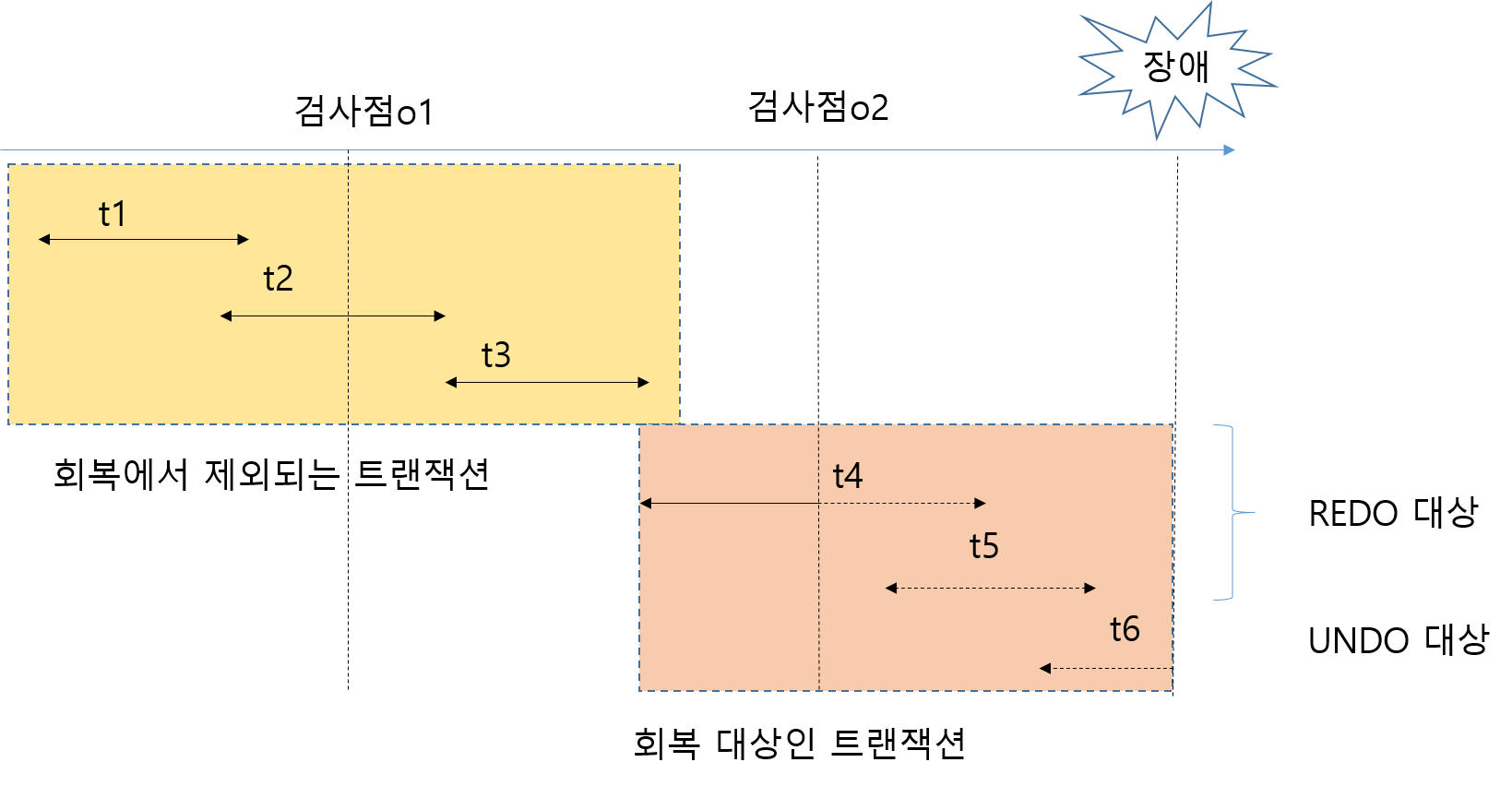
라. 그림자페이지(Shadow Paging) 기법
- 정의: 로그를 이용하지 않고 데이터베이스에 대한 페이지 테이블 전체를 교체하는 방법으로 로그 레코드를 출력하는 오버헤드를 없애고, 디스크 접근횟수를 줄이기 위한 방법으로 2개의 페이지 테이블 (현 페이지와 그림자 페이지)을 유지하고, 트랜잭션 실행 중에는 현 페이지 테이블만을 사용하는 것으로 Undo 및 Redo 연산이 필요 없는 방법이다.
- 수행방법
1) 트랜잭션이 실행되는 동안 현재 페이지 테이블과 그림자 페이지 테이블을 이용
2) 현재 페이지 테이블은 주기억장치, 그림자 페이지 테이블은 하드디스크에 저장함.
3) 데이터베이스 트랜잭션의 시작시점에 현재 페이지 테이블의 내용과 동일한 그림자 페이지 테이블을 생성함.
4) 트랜잭션의 변경 연산이 수행되면, 현재 페이지 테이블의 내용만 변경하고 그림자 페이지 테이블의 내용은 변경하지 않음.
5) 트랜잭션이 성공적으로 완료될 경우, 현재 페이지 테이블의 내용을 그림자 페이지 테이블의 내용으로 저장함.
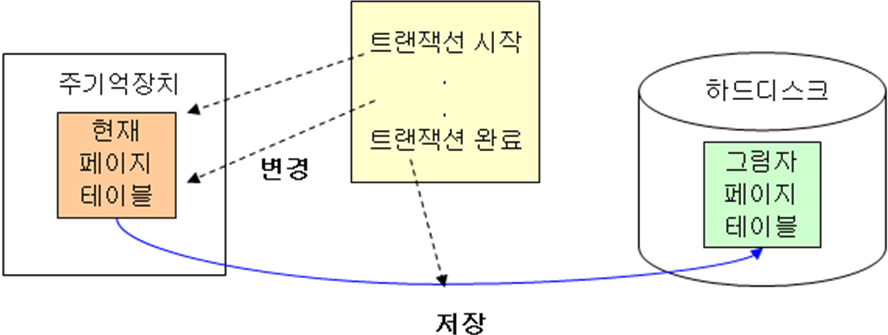
-복구방법
. 수정된 데이터베이스 페이지를 반환하고, 현재의 페이지 테이블을 폐기한다.
. 그림자 페이지 테이블을 현재 페이지 테이블로 설정한다.
-그림자 페이지 기법의 단점
ㆍ 데이터 단편 (data fragmentation)
ㆍ 쓰레기 수집 (garbage collection)
ㆍ 병행 트랜잭션 (concurrent transaction) 지원이 곤란
=> 병행수행환경에서는 로그와 검사시점 기법을 함께 사용
마. ARIES 회복 알고리즘
- 기본 개념
- REDO 중 역사 반복(Repeating history): 붕괴가 발생했을 때의 데이터베이스 상태를 복구하기 위하여 붕괴 발생 이전에 수행했던 모든 연산을 다시 한번 수행. 붕괴가 발생했을 때 완료되지 않은 상태였던 (진행 트랜잭션)은 UNDO 된다.
- UNDO 중 로깅: UNDO를 할 때에도 로깅을 함으로써 회복을 수행하는 도중에 실패하여 회복을 다시 시작할 때에 이미 완료된 UNDO 연산은 반복하지 않는다.
- 주요 3단계
- 분석단계: 붕괴가 발생한 시점에 버퍼에 있는 수정된 페이지와 진행 트랜잭션을 파악, REDO가 시작되어야 하는 로그의 위치를 결정
- REDO 단계: 분석 단계에서 결정한 REDO 시작 위치의 로그로부터 로그가 끝날 때 까지 REDO를 수행, REDO 된 로그 레코드의 리스트를 관리하여 불 필요한 REDO 연산이 수행되지 않도록 한다.
- UNDO 단계: 로그를 역순으로 읽으면서 진행 트랜잭션의 연산을 역순으로 UNDO 한다.
- 회복을 위해 필요한 정보
- 로그: 페이지에 대한 갱신(write), 트랜잭션 완료(commit), 트랜잭션 철회(abort), 갱신에 대한 UNDO, 트랜잭션 종료(end) 시 기록, 각 로그 레코드마다 로그 순차번호(LSN)가 할당
(LSN: 디스크에 저장된 로그 레코드의 주소로서 단조 증가 – Log Sequence Number)
- 트랜잭션 테이블: 진행 트랜잭션에 대한 정보(트랜잭션 식별자, 트랜잭션 상태, 해당 트랜잭션의 가장 최근 로그레코드의 LSN)가 관리
- 오손 페이지 테이블: 버퍼에 있는 오손 페이지에 대한 정보(페이지 식별자, 해당 페이지에 대한 가장 최근 로그 레코드 LSN)가 관리
- ARIES에서의 검사점 기록
- 로그에 BEGIN_CHECKPOINT 레코드를 기록하기
- 로그에 END_CHECKPOINT 레코드를 기록하기
(트랜잭션 테이블과 오손 페이지 테이블의 내용도 함께 저장)
- 특수 파일에 BEGIN_CHECKPOINT 레코드의 LSN을 기록
바. 다중 데이터베이스에서의 회복
가. 다중 데이터베이스 트랜잭션
- 여러 개의 데이터베이스를 액세스하는 트랜잭션으로 이 때 각각의 DBMS들은 서로 다른 회복 기법과 트랜잭션 관리자를 사용할 수 있음
- 원자성을 유지하기 위하여 2단계 완료 프로토콜을 사용
. 모든 참여 데이터베이스가 트랜잭션을 완료하도록 하거나 또는 어느 하나도 완료하지 않도록 한다.
. 어떤 참여 데이터베이스에 고장이 발생하더라도 트랜잭션이 완료된 상태 또는 철회된 상태로의 회복은 항상 가능
나. 2단계 완료 프로토콜 (two-phase commit protocol)
- 1단계
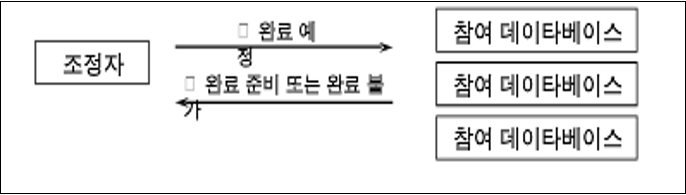
- 2단계: 모든 참여 데이터베이스가 “완료 준비” 되었으면 조정자는 “완료” 신호를 보낸다. 하나 이상의 참여 데이터베이스가 “완료 불가” 신호를 보내면 조정자는 “철회” 신호를 보낸다.
4. 효과적인 데이터베이스 백업과 회복을 위한 고려사항
- 백업 전략 수립 및 주기적인 백업 실행
- 자동화 백업 및 복구도구를 사용하여 생산성 향상
- 재해복구 솔루션을 도입 중단 없는 비즈니스 체계수립
5. 데이터베이스 복구 옵션
가. DBMS H/W 적인 고장으로 인한 장애에 대한 데이터 회복
1)HDD 문제 발생에 대한 복구 대책
- 주로 사용되는 RAID 구성 1+0 구성이나 기타 레이드 구성을 통한 HDD장애 발생에 대하여 대비한다.
2) N/W 문제 발생에 대한 복구 대책
- H/W 적인 복구 방안 : 라인에 대한 이중화를 통한 복구 대책
- S/W 적인 복구 방안 : 1개의 라인에 대하여 2개 라인처럼 사용 할 수 있게 설정 (1개의 물리적 라인에 IP 2개 설정을 통한 S/W상의 독립적 동작 : Deadlock에 대한 대비 가능)
3) IP의 설정은 2개가 아닌 그 이상도 가능함
- H/W + S/W 복구 방안 : 위의 2가지 방안에 대하여 모두 설정
1) 스토리지 서버를 통한 HDD 핫스왑 기능 구현
- 핫스왑 : HDD의 장애 시 전원이 켜진 상태에서 HDD 교체가 가능함
(미러링에 대한 RAID가 스토리지 서버에서 구현가능)
나. 데이터베이스 복구 알고리즘
1) 동기적/비동기적 갱신에 의하여 데이터 베이스 복구 알고리즘이 분류됨
2) 동기적 갱신(Synchronous I/O) - 트랜잭션 실행 내용인 데이터베이스 버퍼를 저장매체에 동기적으로 기록
3) 비동기적(Asynchronous I/O) - 트랜잭션이 완료된 내용을 일정 시간이나 작업량에 따라 시간 차이를 두고 데이터베이스 버퍼 내용을 저장매체에 기록
|
유형 |
기본개념 |
|
NO-UNDO / REDO |
-데이터베이스 버퍼의 내용을 비동기적으로 갱신하는 경우의 데이터베이스 복구 알고리즘 -NO-UNDO : 데이터베이스 변경 내용이 트랜잭션이 완료 이전에 기록되지 않으므로 취소할 필요가 없음 -REDO : 데이터베이스 버퍼에 기록되고 저장 매체에 기록되지 않는 상태에서 시스템이 파손되었을때 트랜잭션의 내용을 재실행해야 함. |
|
UNDO / REDO |
-데이터베이스 버퍼의 내용을 동기적으로 갱신하는 경우 데이터베이스 복구 알고리즘 -UNDO : 트랜잭션들이 완료되기 이전에 시스템 파손이 발생할 경우 변경된 내용을 취소 -NO-REDO : 데이터베이스 버퍼 내용을 모두 동시적으로 기록하므로 트랜잭션 내용을 재실행할 필요가 없음. |
|
UNDO/REDO |
-데이터베이스 버퍼의 내용을 동기/비동기적으로 갱신할 경우 |
|
NO-UNDO / NO-REDO |
-데이터베이스 버퍼의 내용을 동시적으로 저장 매체에 기록하나 데이터베이스와는 다른 영역에 기록하는 경우임. -항상 트랜잭션의 실행상태와 데이터베이스의 내용이 일치하며 따라서 데이터베이스 버퍼의 내용을 취소하거나 재실행할 필요가 없음. |