분산 데이터베이스
태그 :
- 개념
- -논리적으로 같은 시스템에 속하지만, 컴퓨터 네트워크를 통해 물리적으로 분산되어 있는 데이터들의 모임. - 통신망, 자원분산, 투명성 제공, 여러 DB, 논리적 통합, 물리적 Site 별로 분산된 DBMS DB 기술과 Network 기술과의 융화 - 분산 DBMS : 데이터베이스를 관리하고 데이터의 분산을 사용자에게 투명하게 만들어 주는 소프트웨어 시스템
1. 개요
가) 정의
- 논리적으로 같은 시스템에 속하지만, 컴퓨터 네트워크를 통해 물리적으로 분산되어 있는 데이터들의 모임.
- 통신망, 자원분산, 투명성 제공, 여러 DB, 논리적 통합, 물리적 Site 별로 분산된 DBMS DB 기술과 Network 기술과의 융화
- 분산 DBMS : 데이터베이스를 관리하고 데이터의 분산을 사용자에게 투명하게 만들어 주는 소프트웨어 시스템
나) 배경
- 기업의 성장에 따른 조직의 분권화, 유연한 확장성
- 지역별, 부문별 분산 정보의 통합처리 필요성
- 컴퓨터 및 통신망, 분산처리 기술의 발달
다) 목적
- 데이터 처리의 지역화 : 통신 비용 감소 및 데이터 처리 집중화 방지
- 데이터 운영 및 관리의 지역화 : 데이터에 대한 이해도가 높은 집단이 관리
- 데이터 처리 부하의 분산 및 병렬 데이터 처리 : 데이터 처리 속도 향상
- 데이터의 가용성과 신뢰성 향상 : 데이터를 복제
라) 장/단점
|
구분 |
내용 |
|
장점 |
-. 빠른 속도와 통신비 절감 -. 데이터의 가용성 및 신뢰성 -. 시스템 규모의 적정한 조절(용량 확장) -. 지역 업무에 대한 책임 한계 명확 |
|
단점 |
-. S/W 설계 및 관리의 복잡성과 비용증가 -. 데이터 무결성 위험 -. 다양한 자원에 따른 구축 비용 증가 -. 통신망에 따른 제약 사항 |
2. 분산데이터베이스 구조
가) 구성
물리적으로 떨어진 데이터베이스를 네트워크를 통해 논리적으로 연결된 단일 데이터베이스 이미지를 보여주고 분리된 작업 처리를 수행하는 데이터베이스

- 사상
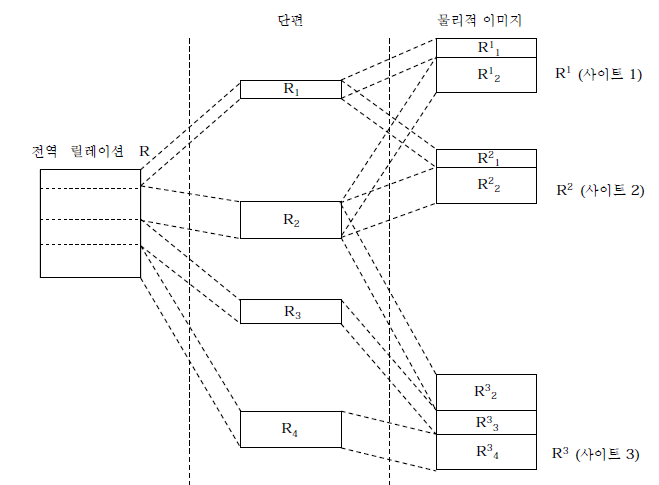
- 단편화
|
구분 |
설명 |
|
수평적 단편화 |
ㆍ조건에 따라 몇 개의 부분집합으로 분할하며, 각 단편은 전역 릴레이션에 대한 실렉션 연산으로 정의
ㆍ 유니온 연산으로 회복 가능
ㆍ 프레디킷들이 서로 배타적이야 함 (분리성 조건)
ㆍ데이타 객체의 값이 변경되면 소속되는 단편도 변경되어야 함 ⇒ 동적 단편화 |
|
수직적 단편화 |
ㆍ 릴레이션의 에트리뷰트들을 그룹화하며, 각 단편은 전역 릴레이션에 대해 프로젝션 연산으로 정의
ㆍ자연 조인 연산으로 회복 가능
ㆍ회복성을 위해 기본 키를 각 단편에 포함 (기본 키 중복)
ㆍ데이타 객체의 값이 변경되더라도 아무런 영향 주지 않음 ⇒ 정적 단편화 |






|
구분 |
설명 |
|
혼합 단편화 |
ㆍ수평적 단편화와 수직적 단편화 혼용 ㆍ각 단편은 실렉션과 프로젝션 연산을 전역 릴레이션에 혼용하여 정의
ㆍ조인과 유니온을 적절한 순서로 적용함으로써 회복 가능
ㆍ릴레이션 R의 혼합 단편에 대한 명세 - 실렉션과 프로젝션으로 표현 가능
- Cond = True이고 A-list =attr(R)이면 Ri는 수직 단편 - Cond ≠ True이고 A-list = attr(R)이면 Ri는 수평 단편 - Cond ≠ True이고 A-list = attr(R)이면 Ri는 혼합 단편 |



나) 분산데이터베이스 성격 (전통적 Local DB vs 분산DB)
- 완전성(completeness) : 전역 릴레이션의 모든 데이타는 반드시 어느 한 단편으로 사상되어야 함
- 회복성(reconstruction) : 단편화된 전역 릴레이션은 다시 원 전역 릴레이션으로 회복이 가능해야 함
- 분리성(disjointness) : 한 전역 릴레이션의 단편들은 중복되게 정의되지 않음 (수직적 단편화 예외)
|
구분 |
전통적 Local DB |
분산DB |
|
통제방식 |
중앙 통제 방식 사용, 전역 DBA |
지역자치성, 지역 DBA |
|
데이터형태 |
데이터 독립성, 개념적 스키마 |
데이터 독립성 및 분산, 은폐성(독립성) 강조 |
|
데이터중복성 |
중복성 감소 요구 비일관성 배제 데이터 공유를 통한 중복도 감소 |
중복성 바람직 지역성 가용도 |
|
트랜잭션처리 |
무결성 회복 동시성제어 |
원자적 트랜잭션 Fault 및 동기화 문제해결이 매우 어려움 |
|
비밀 및 보안 |
DBA가 중앙 통제 역할을 하여 정당한 액세스만 허용 |
지역적 비밀 / 보안 처리 |
다) 분산데이터베이스의 주요 특성
|
주요 특성 |
내용 |
|
Multiplicity |
리소스를 각 노드에 분산시킨다. |
|
Message Passing |
분산된 요소들은 네트워크를 통해서 메시지를 교환한다. |
|
Local Autonomy |
시스템 구성요소들은 어느 정도 자율성을 보장한다. |
|
System Transparency |
사용자는 물리적인 위치를 알지 못한 채 리소스를 사용한다. |
|
Unified control |
자율성을 보장하면서 전체 policy의 통합적인 제어 기능이 가능하다. |
라) 분산데이터베이스의 투명성
분산데이터베이스의 경우 분산 데이터 독립성을 추구해야 함. 즉, 이것은 사용자가 마치 데이터베이스가 분산되어 있지 않은 것과 같이 응용 프로그램을 작성할 수 있는 것을 말함. 이를 지원하는 기법이 분산 투명성임.
|
투명성 |
주요 내용 |
|
분할투명성 |
하나의 릴레이션이 여러 단편으로 분할되어 각 단편의 사본이 여러 시스템에 저장되어 있음을 인식할 필요가 있음.
가)단편화 - 하나의 릴레이션을 보다 작은 단편(fragment)으로 나누어 또 다른 릴레이션으로 취급 - 성능, 가용성, 신뢰성의 이유로 수행 - 데이타 중복의 단점 보완 . 각 사본은 릴레이션 전체가 아니라 그것의 일부가 되어 저장 . 적은 공간으로 관리해야 될 데이타 아이템 수 감소 나)단편화의 종류 - 수평적 단편화(horizontal fragmentation) : 실렉션 이용 - 수직적 단편화(vertical fragmentation) : 프로젝션 이용
다) 데이타베이스 객체가 단편화될 때 필요한 요건 - 릴레이션 전체에 대한 질의문을 서브 릴레이션에 대해 처리할 수 있어야 함 . 릴레이션에 대해 명세된 질의문을 단편을 이용해 처리할 수 있는 질의문 처리 전략 ⇒ 보통 전역 질의문(global query)을 여러 개의 단편 질의문(fragment query)으로 변환하여 처리할 수 있는 기법 필요 - 사용자는 데이타 단편화에 대해 전혀 인식하지 않고 데이타에 접근할 수 있어야 함 라) 단편화 투명성 - 사용자로 하여금 데이타가 단편화되지 않은 것처럼 사용할 수 있도록 해줌 |
|
위치투명성 |
고객이 사용하려는 데이터의 저장 장소를 명시할 필요가 없음. 위치에 관계없이 동일한 명령을 사용하여 데이터에 접근 사용자나 응용 프로그램이 접근하려는 데이타가 어디, 즉 어떤 사이트에 저장되어 있는지 알 필요가 없음 위치 정보는 시스템 카탈로그로 시스템이 관리 다른 사이트의 데이타 접근에 대한 요청 - 데이타를 자기 사이트로 가져와서 지역 처리를 하거나 - 데이타 접근 요청 트랜잭션을 데이타가 있는 다른 사이트로 보내 처리하여 - 결과만 자기 사이트에 가져오거나 위 두 방법을 종합하여 처리 위 두 방법을 종합하여 처리 |
|
지역사상투명성 |
지역DBMS와 물리적 데이터베이스 사이의 사상이 보장됨에 따라 각 지역 시스템 이름과 무관한 이름이 사용 |
|
중복투명성 |
데이터베이스 객체가 여러 시스템에 중복되어 존재함에도 고객과는 무관하게 데이터 일관성이 유지됨 가) 데이타 중복: 하나의 논리적 데이타 아이템에 대해 그 물리적인 값이 상이한 노드에 저장 나)사본의 위치 식별과 관리를 사용자가 아닌 시스템이 관리 다) 성능 향상, 가용성(availability)의 증진
|
|
장애투명성 |
데이터베이스 객체가 여러 시스템에 중복되어 존재함에도 고객과는 무관하게 데이터 일관성이 유지됨. |
|
병행투명성 |
여러 고객의 응용 프로그램이 동시에 분산 데이터베이스에 대한 트랜잭션을 수행하는 경우에도 결과에 이상이 없음. |
마) 분할 결정 요소
|
주요 특성 |
내용 |
|
분산지향 |
지역 내 활용 데이터 네트워크 전송이 복잡하거나 전송비용이 큰 데이터 |
|
집중지향 |
공동 사용 데이터 및 고도의 보안성을 요구하는 데이터 |
|
중복지향 |
전송 속도, 응답속도, 활용도 및 안정성을 요구하는 데이터 |
바) 설계 방식에 따른 분류
|
주요 특성 |
내용 |
|
Top – Down |
중앙 집중 데이터베이스 설계와 같이 전체 설계 후 분산 설계 동일 분산 데이터베이스 설계 |
|
Bottom – Up |
지역별로 설계 후 전사적인 관점에서 통합 설계 이질분산 데이터베이스 설계, 기존 데이터베이스 통합 시 사용 |
|
Hybrid |
데이터베이스 통합 시에 양 방식을 혼합하여 활동함 |
사) 데이터 배치 형태
|
분할 방식 |
내용 |
|
수평분할 |
1. 정의 : 한 관계의 레코드를 분할, 둘 이상의 서로 다른 장소에 저장 2. 비고 : 여러 지역에서 유사한 업무를 수행하되 그 대상이 다른 경우 |
|
수직분할 |
1. 정의 : 한 관계의 속성을 분할하여 둘 이상의 서로 다른 장소에 저장 2. 비고 : 서로 다른 지역의 업무에서 요구되는 데이터의 속성이 다른 경우에 유효한 전략임 |
|
중복 |
1. 정의 : 동일한 데이터 사본을 둘 이상의 장소에 중복하여 저장 2. 비고 : 빠른 응답속도와 통신 비용을 절감할 수 있음. 데이터의 가용성과 신뢰성이 증가됨. 데이터 갱신이 복잡하고 비용이 높음. 저장공간이 빠르게 증가되고 있음. |
3. 분산 DB 질의어처리
가. 전략선택기준 & 중복과 단편에 대한 질의어 처리
|
구분 |
설명 |
|
|
전략선택기준 |
ㆍ디스크 접근 횟수 최소화 ㆍ네트워크 상의 데이터 전송 비용 ㆍ여러 사이트에서 병렬 처리함으로써 얻는 이점 ㆍ짧은 답변 시간 |
ㆍ고려사항 -가능한 여러 처리 전략 가운데 성능이 좋은 하나의 처리 전략을 어떻게 선택 하는가? - 각 전략을 어떻게 평가하는가? |
|
중복과 단편에 대한 질의어 처리 |
-질의문에 대한 학생 전역 릴레이션 : 학생 = 학생1 ∪ 학생2 ㆍ 단편화된 데이터 * σ 학년=2(학생1) ∪ σ 학년=2(학생2) * σ 학년=2(학생1 ∪ 학생2) -단편 데이터 ㆍ 질의어 전송 혹은 데이터 전송 -중복 데이터 ㆍ 전송 비용이 가장 작은 사본을 전성
|
|


단순 조인 & 병렬 조인 & 세미 조인 전략
|
구분 |
설명 |
|
|
단순조인 |
ㆍ릴레이션 S,C,E가 각각 사이트 SS, SC, SE에 저장 ㆍ사용자가 사이트 SU에서 질의한 경우를 가정 ㆍ질의문은 S C E의 자연 조인을 필요로 할 때
① 릴레이션 S,C,E를 모두 SU에 전송한 뒤 지역 처리 ② 릴레이션 S를 SC에 전송하여 S C를 계산 다음에 이조인 결과 (S C)를 SE에 전송하여 (S C) E를 계산 그 결과, ((S C) E)를 SU에 전송 ③ 위의 방법에서 릴레이션의 위치가 서로 바뀐 혼합된 형태로 처리할 수 있음
|
-고려사항 ㆍ전송되는 데이터 양 ㆍ전송된 데이터에 대한 인덱스의 재구성 비용이 큼 ㆍ어느 한 방법도 항상 최적일 수 없음 |
|
병렬 조인 |
ㆍ사이트 Su에서의 질의 ㆍNeed R1 R2 R3 R4 : R1 는 사이트 Si에 저장
ㆍ파이프라인식 조인 기법 - 이전 단계에서의 부분적인 결과를 이용하여 완전히 끝날 때까지 기다리지 않고 병렬 수행 |
|
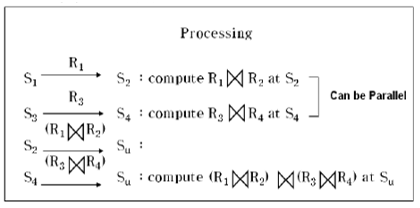
|
구분 |
설명 |
|
세미 조인 |
ㆍR(X) 과 S(Y)의 세미조인, R S R S = ㆍR(X)는 사이트 에 S(Y)는 사이트에 에 저장 - 결과는 사이트로 ㆍR S ① Temp1 ← at - Select tuples with joining attributes only ② Temp1을 로 전송 ③ Temp2 ← S Temp1 at (=S R) ④ Temp2을 로 전송 ⑤ Result ← R Temp2 at ㆍ 이 전략이 유용한 경우 ㆍ 조인 가능 투플 수 << 전체 투플 수 ㆍ 아주 적은 수의 투플만 조인에 참여할 때 |
4. 분산 DB 병행제어
가. 병행제어 기법
|
구분 |
내용 |
|
로킹 기법 |
중앙 데이타베이스 환경에서의 로킹 규약 그대로 사용 가능 - 수정해야 하는 것 : 로크 관리자가 중복된 데이타 처리 가능하도록 구현 트랜잭션이 접근하는 모든 객체에 대해 로크를 걸고 트랜잭션이 끝날 때까지 유지한다면, 그러한 트랜잭션들의 병행 수행은 직렬 가능함 즉, 직렬 수행과 동등 로킹 규약 - A를 읽기 위해 트랜잭션은 반드시 A의 사본 중 최소 하나에 대해(공유)로크를 획득해야 함 - A를 쓰기 위해 트랜잭션은 반드시 A의 모든 사본에 대해 (배타적)로크를 획득해야 함 - 로크 획득 후 , 트랜잭션이 완료되기 전까지 로크를 해제해서는 안 됨 개선 사항 - 모든 사본을 로크할 필요가 없으며, 또는 완료할 때까지 로크할 필요 없음 |
|
단일 로크 관리자 (single lock_ma nager) |
데이타가 중복되어 있는 상황에서 특정 사이트 Si에 하나의 로크 관리자 지정, 유지 데이타에 대한 모든 lock와 unlock 요청은 사이트 Si 에서 처리 트랜잭션이 데이타 아이템을 로크하려면 사이트 Si에 로크 요청 - 로크 관리자는 로크 요청이 즉시 허락될 수 있는지 아닌지 결정 . 허락 가능하면 로크 요청을 한 사이트에 메시지 전송 . 허락 불가능하면 로크 요청을 허락될 수 있을 때까지 대기 후 메시지 전송 데이타 아이템의 검색 - 한 트랜잭션이 사이트 Si로부터 shared-lock을 허락받으면 이 데이타 아이템의 어떤 사본을 판독해도 됨 - 데이타 아이템을 갱신하기 위해 exclusive-lock을 허락받은 경우 분산 데이타베이스 관리 시스템은 로크 해제 전 그 데이타 아이템의 모든 사본이 정확히 갱신되게끔 책임져야 함 |
|
분산 로크 관리자 (distribu ted lock_ma nger) |
로크 관리자의 기능을 여러 사이트에 분산 지역 로크 관리자(local lock_manager) - 각 사이트에 있는 로크 관리자 - 해당 사이트에 저장된 데이타 아이템에 대한 lock과 unlock 요청 처리 한 트랜잭션이 다른 사이트에는 없고 사이트 Si에만 있는 데이타 아이템에 대해 lock하기 원할 경우 - lock 요청 메시지를 사이트 Si의 로크 관리자에게 보냄 - 데이타 아이템이 양립될 수 없는 타입의 로크가 걸려있으면 이 요청은 허락 가능할 때까지 보류 - 로크 요청 허락이 결정되면 로크 관리자는 로크 요청 허락 메시지 전송 |
나. 단일 로크관리자 vs 분산 로크관리자
|
분 |
장점 |
단점 |
|
단일 로크 관리자 (single lock_manager) |
처리가 간단 - lock 요청에 두 개의 메시지, unlock 요청에 하나의 메시지만 필요 교착상태 처리 간단 - lock과 unlock 요청이 한 사이트에서만 처리 |
병목현상 - 모든 요구가 한 사이트 Si로 집중 취약점 - 사이트 Si의 장애 시 처리가 중지되던지 회복 기법을 기동해야 함 |
|
분산 로크 관리자 (distributed lock_manger) |
단순한 구현 단일 로크 관리자에서의 병목 현상 없음 비교적 적은 오버헤드 - lock 요청에 대해 두 개의 메시지 교환 필요 - unlock 요청에 대해 하나의 메시지 교환 필요 |
교착상태 처리 복잡 - lock과 unlock 요청이 한 사이트에서만 처리되는 것이 아님 - 한 사이트 내에서는 교착상태가 없더라도 여러 사이트에 걸친 교착상태 존재 가능 |
다. 기본사본과 과반수 규약
|
구분 |
내용 |
|
기본 사본 |
중복 저장된 데이타 중에 하나를 기본 사본으로 지정 각 객체마다 기본 사이트가 다를 수 있음 트랜잭션이 데이타 아이템 x에 대해 로크가 필요하면 x의 기본 사이트에 로크 요청 → 교착상태 문제점 -기본사본의 장애 → 다른 사본을 가지고 있는 사이트를 실제로 접근할 수 있는데도 결과적으로 x를 접근할 수 없는 문제 발생 |
|
과반수 규약 |
각 사이트마다 하나의 로크 관리자를 유지 x가 저장된 n 사이트의 반수 이상의 사이트에 로크 요청을 보내 허락 받음 -모두 로크하는 것과 같은 효과 중복된 데이타를 비중앙 집중식으로 처리 구현 : 복잡함 -lock 요청을 위해 2(n/2 + 1)개의 메시지 필요 -unlock 요청을 위해 (n/2 + 1)개의 메시지 필요 교착상태 : 처리가 복잡, lock과 unlock이 한 사이트에서 이루어지지 않기 때문 |
라. 시간 스탬프 기법 & 보수적 시간 스탬프 기법
|
구분 |
내용 |
|
시간 스탬프 기법 |
특성 - 각 트랜잭션에 유일한 시간 스탬프를 지정하여 직렬 순서의 기초로 사용 - 논리 계수(logical counter)나 시스템 시계(system clock) 사용 - 연쇄 취소 없이 직렬성을 보장 (시간 스탬프 기법과 2단계 완료규약의 조합) 유일한 시간 스탬프 생성 지역 시간 스탬프(t) 사이트 식별자(s) 아이디어 전역 시간 스탬프 구조 - 트랜잭션이 성공적으로 종료되기 전까지 갱신 연산은 DB에 물리적으로 적용되지 않음 - 취소가 일어날수 있으니 연산을 연기 주의 사항 - 모든 시계가 완전히 정확하지는 않음 ⇒ 지역 시간 스탬프가 시스템 전반에 균형 있게 생성될 수 있도록 하는 것이 필요 - 각 사이트 Si에 논리적 시계(LCi : logical clock)을 정의하여 유일한 시간 스탬프 생성 . 구현 : 새로운 지역 시간 스탬프를 생성한 후 계수 하나 증가 - 여러 개의 논리적 시계를 조화시키는 방법 . 시간 스탬프 를 가진 트랜잭션이 사이트 Si를 방문할 때 t가 현재의 LCi보다 크면 Si의 논리 시계를 t+1로 수정해 놓으면 됨 규약 - TS(T1) < TS(T2) 일 때, 1) T1이 T2에 의해 갱신된 데이타 A를 읽으면 T1은 실행 취소되어 복귀하고 새로운 시간 스탬프와 함께 재시작됨 2) T1 이 T2 가 읽거나 갱신한 데이타 A를 쓰게 되면 T1은 새로운 시간 스탬프와 함께 재시작됨 |
|
보수적 시간 스탬프 기법 |
각 사이트에서 수행될 판독과 기록 요청으로 구성된 read 큐와 write 큐를 각각 유지 TS(Tj) < TS(Ti)일 때 - write(x) 연산이 아직 끝나지 않은 트랜잭션 Ti 가 있을 때 Tj의 read(x) 연산을 지연 - read(x)나 write(x)연산이 아직 끝나지 않은 트랜잭션 Ti가 있을 때 , Tj 의 write(x)연산을 지연 |
전역 교착상태 & 전역 교착상태 탐지 방법
|
구분 |
내용 |
|
|
전역 교착상태 |
|
|
|
전역 교착상태 탐지방법 |
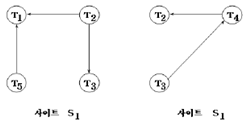
- 지역 대기 그래프 (Local WFG (walt-for graph)) ㆍ한 지역 대기 그래프에 사이클이 없다고 해서 반드시 교착상태가 없다는 것을 의미하지는 않음 ㆍ 필요조건이 아님
|
- 전역대기그래프:전역적으로교착상태발생
|
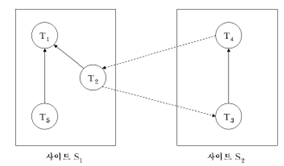
바.중앙 교착상태 탐지 & 계층 교착상태 탐지
|
구분 |
내용 |
|
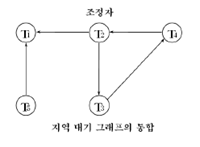
중앙 교착상태 탐지 |
- 지정된 조정자 사이트로서, 교착상태 탐지조정자의역할 - 전역 대기 그래프를 구축하고 유지 (모든 지역 대기 그래프를 통합)
ㆍ지역 대기 그래프에서 새로운 간선이 첨가되거나 삭제될 때 ㆍ일정한 수의 변동이 일어날 때, 사이클 탐지 알고리즘을 가동시킬 필요가 있을 때 - 사이클이 발견되면 취소시킬 희생자를 선정하고 선정된 트랜잭션을 취소 - 문제점 : 거짓 사이클 ㆍ메시지 M1 : T1 취소 or T2 데이터의 로크 해제 M2 : T2, T3에 의해 검유된 자원 요구 ㆍ 만일 M2이 M1 이전에 도착하면 거짓 사이클이 탐지 →만일 T3를 희생자로 선택, T3의 불필요한 복귀 |
|
계층 교착상태 탐지 |
- 교착상태 탐지 조정자들을 트리 형태로 계층적으로 구성 ㆍ단말노드 : 지역 교착 상태 탐지기 (LDD) * 지역 교착상태 탐지 * 잠정적 사이클 정보를 계층상의 직속 상위 NLDD에 전송
* 자기 자식 탐지기들로만 관련된 교착상태를 탐지 ㆍ잠정 대기 그래프를 축소시켜 직속 상위 NLDD에 전송 - 루트 : 최상위 교착상태 탐지기 ㆍ시스템 전체 노드에서 일어난 교착 상태를 탐지 - 성능 : “계층구조의 선택”에 좌우됨 ㆍ점근 요구 패턴에 기반한 사이트 그룹화 ㆍ트랜잭션의 국지성 |

 ㆍ 중간노트 : 비지역 교착상태 탐지기(NLDD)
ㆍ 중간노트 : 비지역 교착상태 탐지기(NLDD)
분산 교착상태 탐지
|
구분 |
내용 |
|
|
분산교착상태 탐지 |
- 각 사이트는 추가된 선으로 각자 지역대기 그래프를 관리 유
• 지역대기 그래프에 노드 Tex가 포함되지 않은 사이클 → 교착상태 • Tex가 포함된 사이클
→ 잠재적 교착 상태(전역적) • site 1이 WPG를 site 2에 보냄 |

 Tex → Ti → Tj → … → Tk → Tex
Tex → Ti → Tj → … → Tk → Tex
5. 2PC (Two Phase Commit)
가. 개념
분산 데이터베이스 환경에서 원자성을 보장하기 위해 분산 트랜잭션에 포함되어 있는 모든 노드가 Commit 하거나 Rollback 하는 메커니즘
나. 필요성
- 분산데이터베이스 환경 하에서 Commit과 Rollback 만으로 여러 지역에 분산된 데이터베이스의 일관성이 보장되지 않음.
- 분산데이터베이스에서는 모든 지역의 데이터베이스에서 트랜잭션이 성공 완료되었음을 확인한 후에 트랜잭션의 처리가 완료되어야 함
다. 실행 주체
|
용어 |
주요 개념 |
|
서버 (Server) |
원격 노드에서 요구하는 데이터를 가지고 있는 노드 조정자 또는 참여자임 |
|
조정자 (Global Coordinator) |
분산 트랜잭션에 참여하는 참여자 목록을 가지며 분산 트랜잭션 및 Global Commit을 시작하는 노드 |
|
참여자 (Participant) |
분산 트랜잭션에서 지역 트랜잭션을 수행하는 서버 조정자의 존재를 알고 그 결정을 따름 |
|
클라이언트 (Client) |
분산 트랜잭션 응용을 실행하는 노드 |
라. 특성
- 여러 단계를 거칠수록 신뢰도는 증가하지만 반대로 오버헤드는 증가
- 각 Note 데이터베이스의 데이터 일치성을 위해서 각 Node 마다 협력 필요
- 2PC는 트랜잭션의 중요한 특성인 Atomicity를 보장하기 위해서 분산데이터베이스에서 이용
마. 2단계 Commit
- 1단계 (Prepare Phase)
Global Coordinator (분산 트랜잭션 및 Global Commit을 시작하는 노드)가 분산 트랜잭션에 참여하는 노드들에 대하여 Prepare 하도록 요청하는 단계
ㆍ 지역노드의 응용프로그램에서 Commit 요구
ㆍGlobal Coordinator가 Commit Point Site(관련된 원격 site) 결정
ㆍGlobal Coordinator가 Prepare Message 전송하고 원격 노드는 Prepared Message Reply
- 2단계 (Commit Phase)
노드에 Commit / Rollback 명령을 보내는 단계
ㆍ결정을 내려야 하는 Coordinator 가 다른 노드로부터 에러보고를 받았을 때에는 Rollback 하라는 것을 알림
ㆍ모두가 Commit 준비되었다는 것을 받았을 경우에는 각 노드에 Commit을 명령함.
사. 동작기법
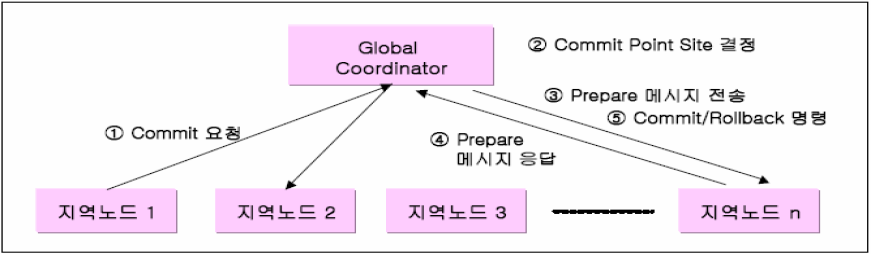
응답메시지 종류
- Prepared : 데이터베이스가 Commit을 할 수 있는 있다고 응답
- Read-only : 읽기 전용 데이터베이스
- Abort : 데이터베이스가 Commit을 수행 할 수 없는 경우 발생
“끝”