SW 신뢰성과 가용성
태그 :
- 개념
- 어떤 기준 시점에서부터 서비스 수행의 지속성에 대한 척도로 장애가 발생하기까지의 시간, 즉 MTTF(Mean Time To Failure)로 표현.
1. 소프트웨어 신뢰성 및 가용성의 개요
가. 소프트웨어 신뢰성(Reliability) 의 정의
어떤 기준 시점에서부터 서비스 수행의 지속성에 대한 척도로 장애가 발생하기까지의 시간, 즉 MTTF(Mean Time To Failure)로 표현.
과거의 자료와 개발상의 자료를 이용하여 측정과 예측이 가능함.
is the ability of a system or component to perform its required functions under stated conditions for a specified period of time.
나. 소프트웨어 가용성(Availability) 의 정의
서비스의 수행과 중단, 두 상태를 왔다 갔다 하는데 관련된 서비스 수행에 대한 척도로 통계적으로 정량화하는 것.
프로그램이 주어진 시점에서 요구사항에 따라 운영되는 확률.
is the degree to which a system or component is operational and accessible when required for use.
2. 소프트웨어 신뢰성 확률 분포 그래프
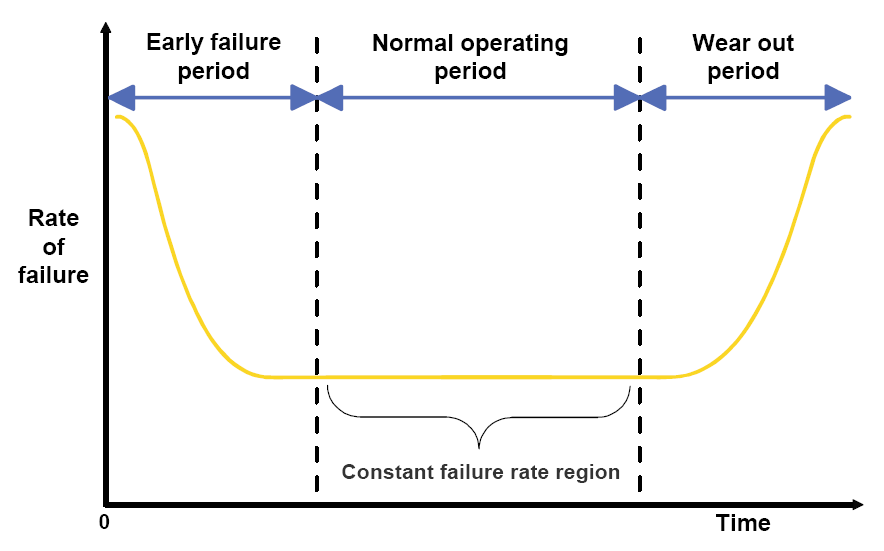
가. 신뢰성 연구에 대한 방향 :
ISO 9126 품질특성에 근거하여 품질 목표에 대한 신뢰성을 확보하는 방법정의
나. 신뢰성 향상방안(국제표준 기준)
1) IEC 61508(기능안전규격 S/W) : 규격안전의 모체에서 정의 IEC 61508-3
2) ISO 26262(자동차 S/W 분야) : 신뢰성 기준을 양자가 계약
적기, 제품출시 양단의 합의점 기준 적용(당사자 책임제)
3) IEEE 62279(철도 S/W 분야) : 26262와 유사한 규정
다. S/W 신뢰성을 향상시키는 방안
Coding Rule 재정을 통한 관리 : ISO C90/C99, Qac/QAC++
잠재적 오류 검출 활동 : 코딩규칙, 인스펙션
S/W unit test 수행 : 동적시험, 단위/통합 test,3자test
Code Coverage : 코드커버리지 범위 측정 및 관리
3. 소프트웨어 가용성에 따른 시간 구조 및 계산사례
가. 가용성 산출을 위한 측정정보
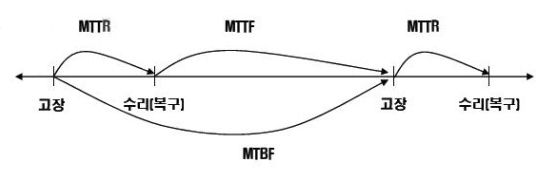
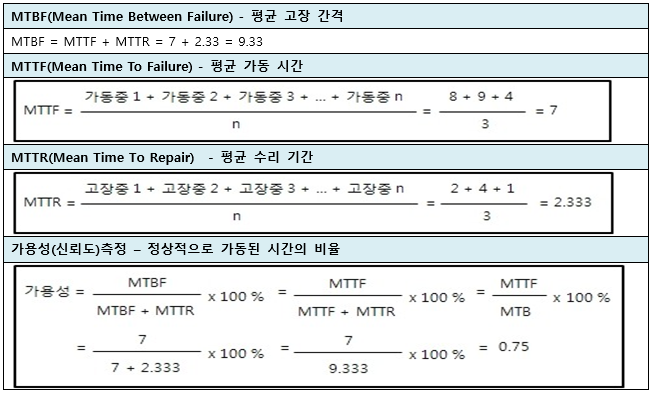
1) MTBF(Mean Time Between Failure) : 평균 고장 간격 (※ 수리가 가능한 시스템에 사용 )
- 시스템이 고장난 후부터 다음 고장이 날때까지의 시간
공식 ☞ MTBF = MTTF + MTTR
2) MTTF(Mean Time To Failure): 평균 가동 시간
- 시스템의 사용 시점부터 고장이 발생할 때까지의 가동 시간 평균 (※일반적으로는 수리 불가 장치에 사용됨. 평균 수명의 개념 )
공식 ☞ MTTF = ( 가동시간1 + 가동시간2 +…+ 가동시간n )/n
3) MTTR(Mean Time To Repair): 평균 수리 시간
- 시스템에 고장이 발생하여 가동하지 못한 시간들의 평균
공식 ☞ MTTR = ( 고장시간1 + 고장시간2 +…+ 고장시간n )/n
4) 가용성(신뢰도)측정 : 정상적으로 가동된 시간의 비율
공식 ☞ MTBF / (MTBF+MTTR) X 100% = MTTF / (MTTF + MTTR) X 100%
= MTTF / MTBF X 100%
나. 가용성 계산사례
문제) 끊임 없이 실행되도록 디자인된 응용 프로그램의 경우, 연속 1000시간을
검사점으로 가정하고 그 동안 1시간씩 두번 오류가 발생한 경우
1) MTBF = 시간 / 오류 발생 회수 = 1000 / 2
2) MTTR = 복구 시간 / 오류 발생 횟수 = 2/2 = 1
3) 가용도 = (( 1000 / 2 ) / (( 1000 / 2 ) + 1 )) * 100 =
( 500 / 501 ) * 100= 0.998 * 100 = 99.8 %
4) 가용성 측정
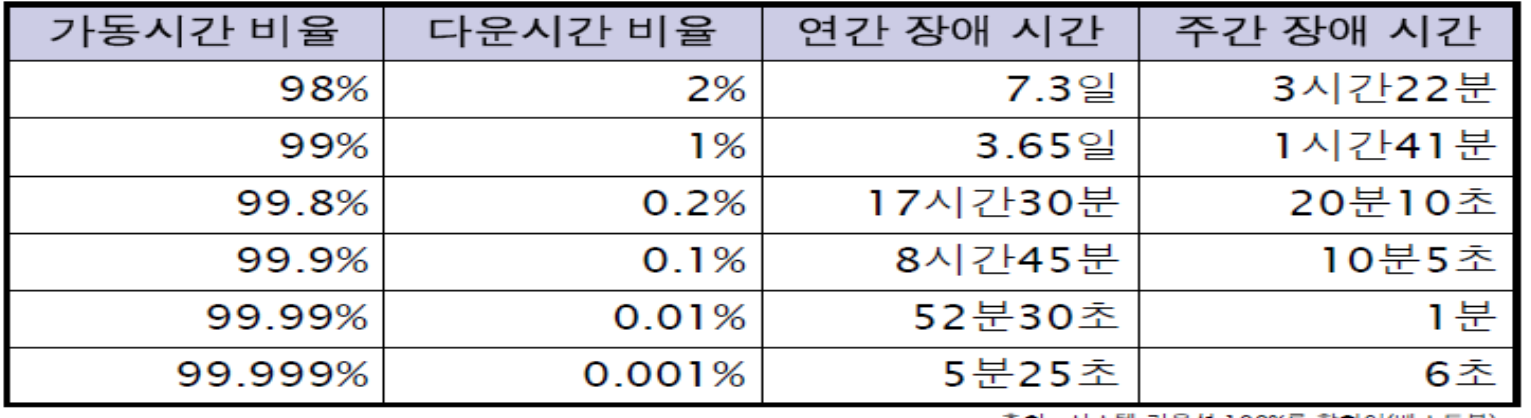
- 연간기준으로 99.9%의 가용성은 연간장애시간 8시간 45분이며, 주간
장애시간은 10분 5초를 의미함.
5) 가용성 측정에 따른 가용성수준계획
- 비즈니스 요구사항을 충족하는 가용성수준을 결정하는 것이며, 대상고객
및 고객의 기대치, 가동중지시간 허용치, 회사 내부프로세스의
서비스의존여부, 일정 및 예산과 같은 사항을 고려하여야 함

문제)
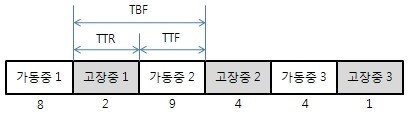
풀이)
4. 가용성 확보전략
가. 가용성 확보 방안
- 가용성 확보 및 유지를 위해서는 결함탐지(Fault Detection), 결함복구(준비/수정, Preparation and Repair), 재가동(Reintroduction), 방지(Prevention)의 방법을 반영한 아키텍처 전략 수립과 시스템 설계가 필요함.
나. 가용성 확보를 위한 전략
|
구분 |
주요 기술 |
내용설명 |
|
결함 탐지 |
Ping & Echo |
서로 다른 프로세스 사이에서 오류를 감지하는 방법으로 컴포넌트가 신호를 보내고 상대편 컴포넌트로부터 정해진 시간 안에 응답이 돌아오는지 관찰함 |
|
Heartbeat |
일정한 시간 간격을 두고 신호(heartbeat)를 내보내고, 신호수신여부에 따라 오류판단 |
|
|
Exception |
한 프로세스 안에서 오류를 감지하는 방법으로 예외를 통해 결함을 인식함 |
|
|
결함복구( 준비/ 수정) |
Voting(투표) |
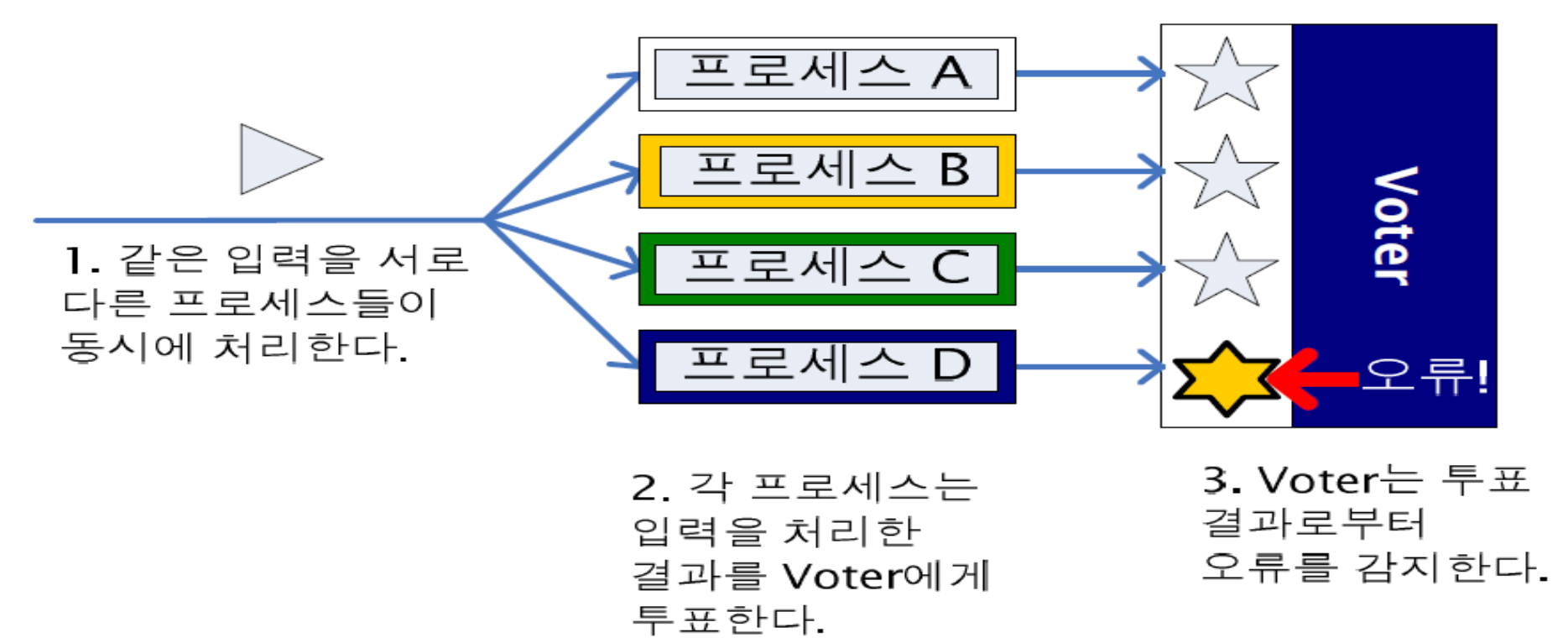
중복된 프로세서에서 실행되는 프로세스들은 모두 같은 입력을 받고, 투표자(voter)에게 보낼 결과값을 각자 연산함. 투표자가 타 프로세서와 다르게 동작하고 있는 프로세서가 있다면 감지하여 제외시킴.
|
|
Active Redundancy (능동 다중화) |
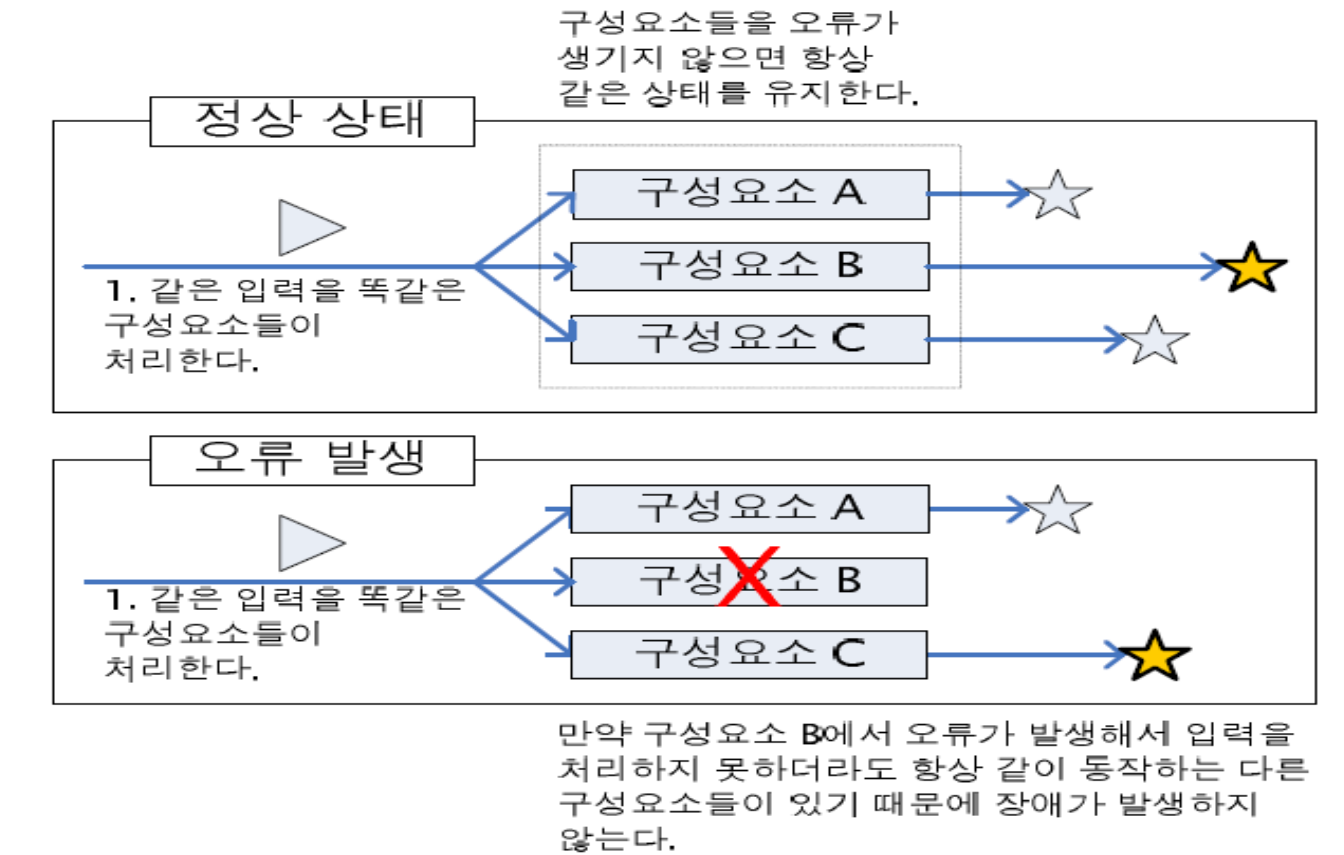
같은 구성요소를 배치하여 오류가 발생하여 처리를 못하더라도 동일한 다른 구성요소에서 처리가능
|
|
|
Passive Redundancy |
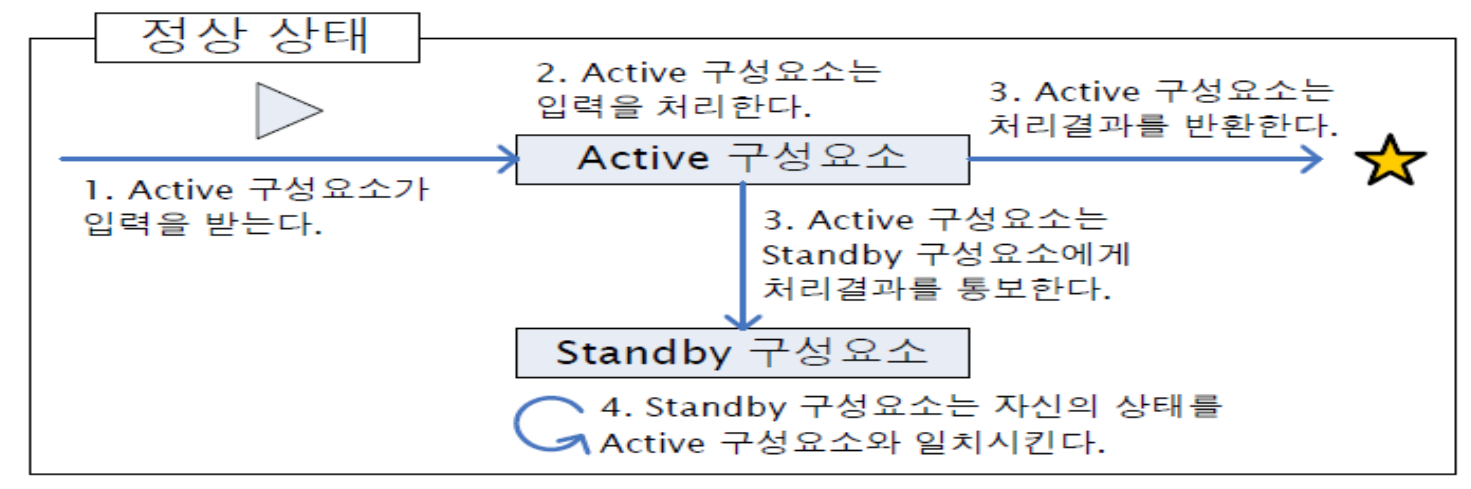
같은 구성요소를 Active와 Standby로 구성하여 처리함.
|
|
|
예비 (Spare) |
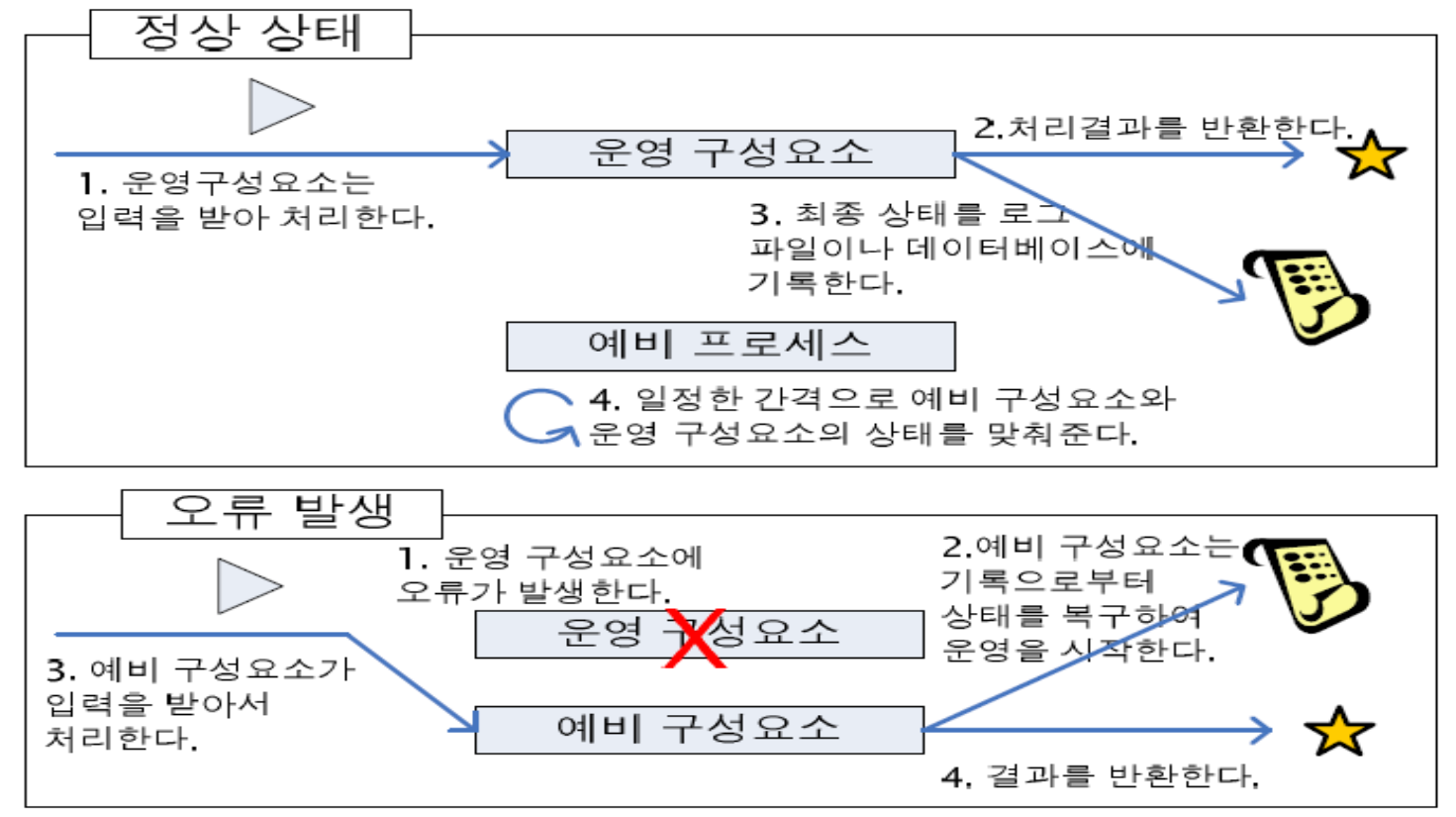
오류가 발생하명 예비구성요소를 통하여 상태를 복구한 후 운영시작
|
|
|
결함복구(재가동) |
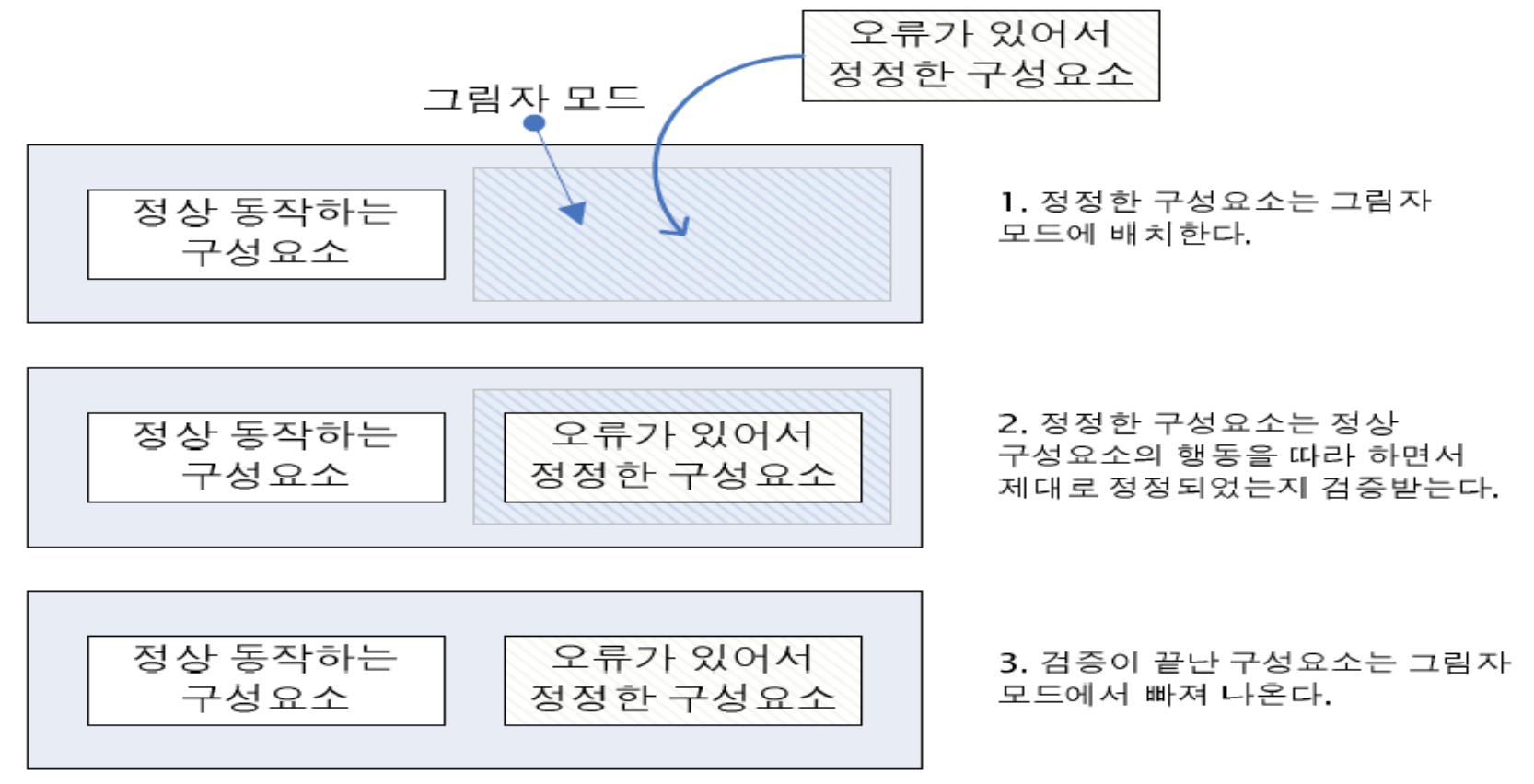
Shadow Operation |
이전에 실패한 컴포넌트 잠시 동안 ‘그림자모드’ 로 작동시켜서 정상 운영 중인 컴포넌트의 동작을 따라 하도록 한 후 다시 서비스로 복귀시킴.
|
|
State resynchronization |
능동 다중화나 수동 다중화에서 오류를 복구한 구성요소가 서비스를 다시 제공하려면 최신 상태로 구성요소의 상태를 재동기화 해야 한다. 재동기화 방법은 견딜 수 있는 다운시간, 회복해야 할 상태의 양과 개수에 따라 달라진다. |
|
|
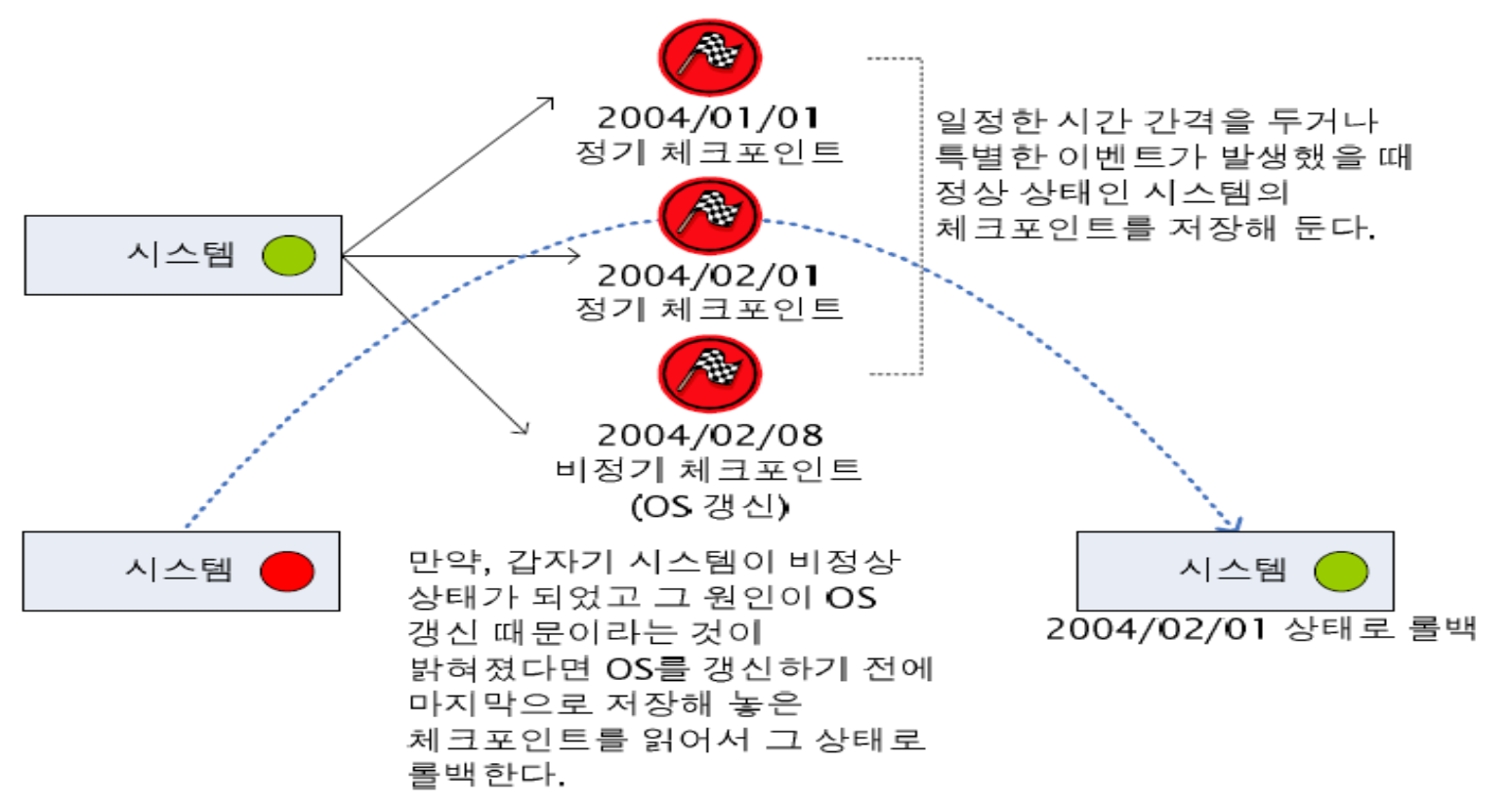
Checkpoint/Rollback |
시스템의 안정적인 상태를 주기적으로 혹은 특정한 이벤트가 발생할 때마다 기록하여 오류 발생시 트랜잭션 로그를 이용하여 복구
|
|
|
결함 방지 |
Removal from service |
실패가 예상될 때 그 실패를 피하기 위한 목적으로 현재 진행 중인 동작에서 특정 컴포넌트를 제거하는 것. 예) 메모리 누수가 발생하고 있는 컴포넌트 재부팅 |
|
Transactions |
일련의 순차적인 절차를 한꺼번에 원상태로 되돌릴 수 있도록 그 절차들을 묶어 놓은 것. |
|
|
Process monitor |
프로세스가 결함을 탐지하면, 감시 프로세스는 동작을 멈춘 프로세스를 삭제하고 새로운 프로세스를 시작시킴 |