Fault Tolerant, High Availability
태그 :
I. 결함 발생시 시스템 정지 없이 연속적 기능을 보장하는 시스템, FTS의 개요
가. FTS(Fault Tolerant System)의 정의
- 하드웨어 또는 소프트웨어의 결함, 오동작, 오류 등이 발생하더라도 설계상에 명시된 기능을 지속적으로 수행할 수 있는 시스템
- 시스템의 가용성, 신뢰성, 안전성 보장
나. FTS의 필요성
- 데이터의 무결성과 일관성 유지
- 시스템 가동률 극대화, 데이터 안전 및 보존 유지
- 시스템고장 등으로 인한 경제, 인명 손실을 막고 사회적혼란에 대한 대처 방안 필요
- 트랜잭션 처리, 실시간 제어, 인간의 안전에 관련된 응용 분야에서 그 중요성이 증대
Ⅱ. FTS의 개념도
가. 결함허용시스템의 개념도
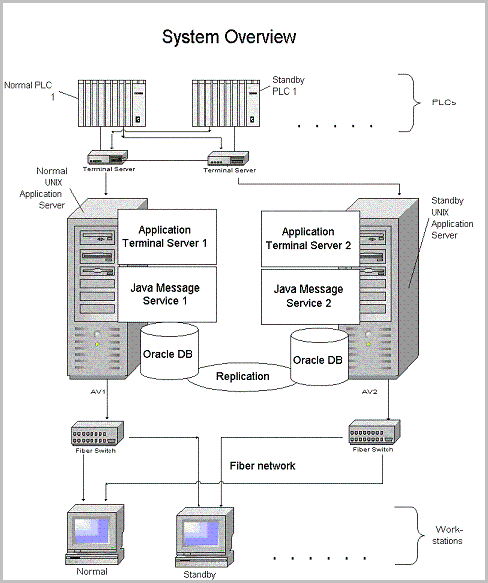
- PLC(Programmable Logic Controller)와 Work-stations과 같은 클라이언트 레이어 에서도 높은 고 가용성이 요구되는 경우 Standby 형태로 시스템 구성
- 서버의 경우 Active Unix Application Server의 모든 기능을 수행할 수 있는 Standby Unix Application Server 배치. DB의 경우 Replication을 통해 복제화
Ⅲ. 가용성 저해 원인과 결함 해결 단계 및 주요구비 기능
가. 가용성 저해 원인
|
구분 |
내용 |
해결방안 |
|---|---|---|
|
응용 시스템 |
-부적절한 Source code -비 효율적 분기 logic -잘못된 sql -Resource 미 반환 |
-표준 개발프로세스 정립 및 개발자 역량 강화 -단위 테스트, 모듈 테스트 |
|
DBMS |
-DB performance 튜닝 부족 -Dead Lock, Latch 경합 |
-주기적인 모니터링 기반 DBMS 최적화 -DB 성능진단 및 튜닝 |
|
H/W |
-물리적 H/W resource 부족, Fault -(firmware, patch)유지보수 미흡 |
-시스템 중요도에 따른 투자 검토 |
|
N/W |
-대량트래픽에 의한 N/W Resource초과, -DDOS, 해킹 등의 보안 침해 -물리적 Fault |
-보안 솔루션 -계획적인 N/W자원 활용. QoS 도입 -이중화 |
나. 결함의 해결 단계
|
단계 |
내용 |
|
결함감지 (Fault Detection) |
- 하드웨어로 구성된 비교기(Compare Logic)를 통하여 수행됨 - 시스템 내에서 Fault가 발생되면 해당 모듈 또는 시스템은 Fault 상태로 들어가게 되고, OS는 각 모든 하드웨어 모듈들의 상태를 분석하여 어느 모듈이 Fault를 유발시켰는가를 분석하여 알아냄 |
|
결함진단 (Fault Diagnosis) |
- Fault가 일시적(Transient)인 것인지 영구(Hard)적인 것인지 판단하여 영구적인 경우 해당 모듈을 시스템 구성에서 제거 |
|
결함통제 (Fault Isolation) |
- 결함으로 인한 오류 파급 차단 |
|
결합복구 (Fault Recovery) |
- Fault를 유발한 모듈을 시스템에서 제거하여 시스템을 재구성 |
다. 결합허용 시스템의 주요 구비기능
|
기능 |
상세내용 |
|---|---|
|
중복성 |
- 시스템의 구성요소 백업, 이중성으로 결함 발생시 대신 동작 - 복구 작업의 지원 |
|
결함검출 |
- 결함 복구를 위한 결함발생 인식 |
|
결함위치확인 |
- 결함의 내용과 위치검출 |
|
결함격리 |
- 결함 발생부분의 격리 |
|
재구성 |
- 결함 발생시에도 정상적 작동 보장 |
|
보수 |
- 고장 부분을 정상 작동에 방해 없이 교체 및 보수 |
|
회복 |
- 교체 및 보수 후 시스템의 동작을 방해 없이 추가 |
|
데이터보존 |
- 정보의 손상 및 유실 방지 |
Ⅳ. 결함허용 기법
가. Hardware 측면
|
기법 |
상세내용 |
|
Checkpoint 기법 |
한 프로세스를 주 프로세서와 보조 프로세서에 중복 할당(중복성의 원리) |
|
Hot standby 방식 |
두 개의 프로세서를 동기 상태에서 프로세스 수행 |
|
Triple modular Redundancy |
3개 이상의 프로세서가 같은 입력에 대하여 동일한 연산 수행 |
|
RAID |
디스크 미러링, 패리티 비트 분산 저장을 통해 결함 허용 |
나. Database 측면
|
기법 |
상세내용 |
|---|---|
|
Rollback (Undo) |
트랜잭션 작업 철회 |
|
Log File |
Commit안된 작업을 로그 파일로 회복 |
|
Check Point |
중간 검사시점을 두어 결함 발견시점 이후만 회복 |
|
Shadow Paging |
트랜잭션 실행 동안 수행 페이지 테이블과 그림자 페이지 테이블을 지속 유지 |
다. 소프트웨어 측면
|
기법 |
상세내용 |
|---|---|
|
Check Pointing |
- S/W 수행 중에 검사시점을 설정하여 오류발생이 발견되면 발생 이전의 검사시점으로 되돌아가서 재 수행 |
|
Recovery Block |
- 재 수행 (Rollback & Retry)에 근거 - 검사시점에서 오류가 발견되면 지정된 이전 검사점으로 되돌아가서 같은 기능을 가진 다른S/W모듈을 수행 |
|
Conversation |
- 재 수행(Rollback & Retry)에 근거한 Recovery Block의 확장형 - 복수의 프로세서 정보를 교환하는 프로세서들 간에 적용 가능한 기법 |
|
Distributed Recovery Block |
- Recovery Block 기법을 분산환경으로 확장 - H/W 결함과 S/W 결함을 동일한 방법으로 대처 |
|
N Self-checking Programming |
- 두 개 이상의 Self-checking 컴포넌트가 수행되면서 하나는 주어진 기능을 수행하고 다른 컴포넌트는 대기상태 |
|
N version Programming |
- H/W 결함허용 기법의 Triple Modular Redundancy와 유사 - N개의 독립적인 S/W 모듈의 수행결과를 비교하여 다수의 수행 결과를 채택 |
라. 데이터 측면
|
기법 |
내용 |
|---|---|
|
Parity Code |
2진 정보 내의 “1’의 개수를 홀수 또는 짝수로 규정하여 결함 감지 |
|
M of N Code |
N bit의 정보 길이에서 “1”의 개수가 반드시 M 개가 되게 하여 결함 감지 |
|
Checksum |
한 블록의 정보내용 합을 추가 |
|
Berger Code |
한 정보의 “1”의 개수를 2진 정보로 추가 |
|
Hamming Error Correcting Code |
결함 감지 및 단일 결함의 교정까지 수행하는 코드 기법 |
Ⅴ. FTS 설계 고려 사항과 활용분야 및 전망
가. 결함허용시스템 설계 고려사항
- 처리방식에 따라 하드웨어 구조와 적용할 기법이 달라짐
- 결함허용 정도에 따라 적용 기법과 소요 자원이 달라짐(일반 응용분야는 단순 결함감지만으로 가능, 고신뢰도 분야는 신속한 결함값 및 복구까지 필요)
- 분야별 결함허용 기법을 조화롭게 활용하여 FTS 구성함
나. FTS 활용분야
|
구분 |
내용 |
|
고 신뢰도 |
핵반응 제어, 우주비행 제어 등 |
|
장기 안정성 |
무인 우주항공 제어 등 |
|
높은 가용성 |
전화교환망, 항공예약시스템 등 |
- 하드웨어 기법 중심, Mirrored Memory, Mirrored Disk, On-line Repairing 기법 사용
다. FTS 향후 전망
- IT 시스템 거대화, 복잡화에 따라 적용대상 증가 전망
- 결함 감지에서 복구/회복까지 완벽하게 만족시키는 각종 기법들 개발
- Ubiquitous, Green IT 2.0 확대 등을 통해 자동화된 생활 환경
Ⅵ. 서비스 연속성 확보를 위한 HA의 개요
가. HA(High Availability) 의 정의
- 두 대 이상의 시스템을 하나의 클러스터로 묶어서 한 시스템의 장애시 클러스터내의 다른 시스템이 신속하게 서비스를 Failover해 최소한의 서비스 중단을 이루려는 메카니즘
나. HA의 필요성
- 서비스 다운타임을 최소화함으로써 가용성을 극대화
- 고가용성으로 기업의 비즈니스 연속성(Business Continuity) 확보
- 기업의 신뢰도 및 이미지 향상
다. HA를 위한 요구사항
- RAS(Reliability, Availability, Serviceability)
- Dynamic Configuration and Upgrade)
- Disaster Recovery
- Single System Image
- 통합운영관리, 저렴한 소유비용(TCO, Total Cost of Ownership)
Ⅶ. HA 구성도
가. HA 구성도
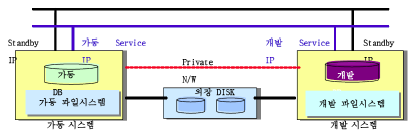
- HA 구성에 참여하는 각 시스템은 2개 이상의 네트워크 카드를 가지면서 네트워크를 통해 상호간의 장애 및 생사 여부를 감시
- Standby Network은 서비스 네트워크 장애시 백업용으로 사용되고, Private Network 은 HA 에 참여하는 시스템들만 통신하는 전용 Network 임
- 외장 디스크는 가동 및 개발 시스템에서 공유할 수 있어야 하며, Concurrent Access 또는 순차적인 Access 방식에 따라 HA 가 다르게 구성
나. HA 구성 유형
|
구 분 |
설 명 |
|
Hot Standby |
- 가장 단순하면서 많이 사용되는 유형 - 가동 시스템과 평상시 대기 상태 또는 개발 시스템으로 운영되는 백업 시스템으로 구성 - 외장 디스크는 가동 시스템에서만 접근 가능하고, 장애 시에만 백업 시스템에서 접근 가능함 |
|
Mutual Takeover |
- 2개 시스템이 각각의 고유한 가동 업무 서비스를 수행하다가 한 서버에 장애가 발생하면 상대 시스템의 자원을 Failover 하여 동시에 2개의 업무를 수행하는 방식 - 장애 발생 시 Failover 에 대비해 각 시스템 2개의 업무를 동시에 서비스할 수 있는 시스템 용량을 갖추도록 고려해야 함 - 외장 디스크는 해당 시스템에서만 접근 가능함 |
|
Concurrent Access |
- 여러 개의 시스템이 동시에 업무를 나누어 병렬 처리하는 방식으로 HA 에 참여하는 시스템 전체가 Active 한 상태로 업무를 수행함 - 한 시스템에 장애가 발생하여도 다른 시스템으로 Failover 하지 않고 가용성을 보장함 |
Ⅷ. HA 상세 구현방식
가. Hot Standby
- 평상시 백업시스템을 구성하여 대기상태를 유지하다가 장애 발생시 자원을 Take-over

나. Mutual take-over
- 각 서버가 별개의 서비스 수행중인 상태에서 특정 서비스에 문제시 해당 서비스를 타 서버로 Take-over

다. Concurrent Access
- 여러 시스템이 동일 업무를 동시에 병렬로 처리하는 방식, 한 시스템 장애 시에 타 시스템으로 서비스를 지속

Ⅸ. HA 동작 방식 및 Fault Tolerant System 과 비교
가. HA 동작 방식
|
장애 상황 |
HA 동작 방식 |
|
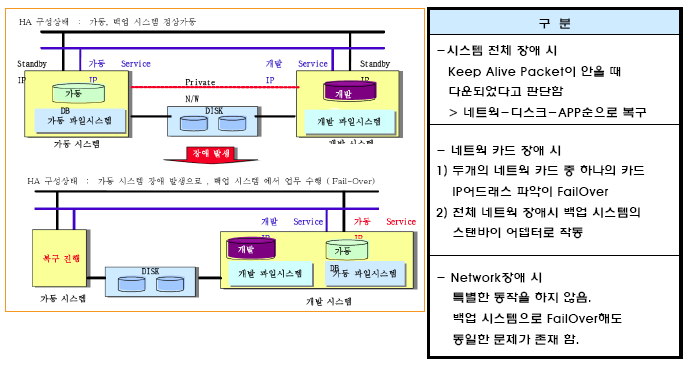
시스템 전체 장애 시 |
- 한 시스템으로부터 keep alive packet이 오지 않는 경우 백업 시스템은 상대 시스템이 Down 되었다고 판단하고 이미 정의된 자원(Volume Group, Filesystems, IP Address,Application)을 Failover - Failover 순서 : 미리정의된 Scripts에의해Network 자원 => Disk 자원 => Application 자원 순서로 진행 됨 |
|
Network Adapter 장애 시 |
- 가동시스템 내의 Service Adapter 장애 시 : 시스템에 Service adapter 와 Standby adapter를 설치 구성한 경우, Service adapter에 장애가 발생하면 Standby adapter가 Service adapter의 IP Address를 Faileover - 가동 시스템내의전체N/W Adapter 장애 시: 백업 시스템의 Standby Adapter로가동 시스템의 Service IP Address가 Failover됨. |
|
TCP/IP Network 장애 시 |
- Network 전체 장애가 발생하는 경우에는 특별한 동작을 하지 않는다 - N/W 전체 장애시에는 백업 시스템으로 Failover해도 동일한 N/W 문제가 존재함 |
나. HA와 Fault Tolerant System과 비교
|
구분 |
FTS |
HA |
|
Failover Time |
0초 |
30 ~ 300초 |
|
동시성 유지보수 |
필요 |
불필요 |
|
시스템 비용 |
10 ~ 20배 |
2배 이상 |
|
어플리케이션 |
제한적 |
대부분 범용제품 |
|
운영체제 |
전용 OS |
범용 OS |
|
하드웨어 |
전용 하드웨어 |
범용 하드웨어 |
Ⅹ. HA의 한계점 및 구축 시 고려사항
가. HA 한계점
- External Disk 자체장애발생 시 HA Solution으로 해결 못함
- 장애 발생으로시 스템이 Down 되지 않는 경우자동 Failover가 되지 않음
- 시스템성능이 저하되는 경우에 자동감지가 불능
- DB 및 Application 이 Down되는 경우에는 일반적으로 Failover하지 않음
- DB 및 Application 자체 Bug일 경우 Failover가 의미 없음
- HA구성에 따른 정보교환으로 시스템의 안정성, 보안성, 성능에 Overhead가 존재함
나. HA 구축 시 고려사항
- HA 구성 방식 및 대상 서버결정
- 백업 서버 Capacity
- HA 대상 시스템들에 대한 OS 자원 및 사용자 자원 동기화
- 보호될 자원 결정 및 자원 동기화
- External Disk의 보호방안(2중화여부)