TCP/IP 혼잡제어
태그 :
- 개념
- - 중간 노드 혹은 네트워크 내에서 링크 대역폭 이상의 데이터가 전송될 때 발생 - 패킷 스위칭 네트워크에서는 여러 사용자가 자원을 공유 - 많은 사용자들이 동시에 너무 많은 데이터를 너무 빨리 전송하는 경우 ㄴ 라우터에서 많은 지연이 일어남 ㄴ 심하면 라우터 버퍼에서 오버 플로우 발생으로 패킷 손실 우려
I. TCP 혼잡제어(Congestion Control)의 개요
가. TCP의 혼잡제어의 개념
- 중간 노드 혹은 네트워크 내에서 링크 대역폭 이상의 데이터가 전송될 때 발생
- 패킷 스위칭 네트워크에서는 여러 사용자가 자원을 공유
- 많은 사용자들이 동시에 너무 많은 데이터를 너무 빨리 전송하는 경우
ㄴ 라우터에서 많은 지연이 일어남
ㄴ 심하면 라우터 버퍼에서 오버 플로우 발생으로 패킷 손실 우려
나. 혼잡제어의 목적
- 네트워크가 수용할 수 있는 이상의 데이터 전송이 이루어 질 때 발생하는 패킷 전송 지연 혹은 패킷 손실 막는 것
다. 혼잡제어의 방식
- 라우터에서 혼잡이 발생했음을 소스 호스트로 알려주는 방식
- 네트워크의 도움 없이 소스 호스트가 확인응답인 Ack 만을 가지고 혼잡발생 여부를 알아서 제어하는 방식 → TCP
라. 혼잡제어의 원인
- 송신자가 데이터를 ‘너무 빠르게’, ‘너무 자주’ 전송함으로서 발생
II. 혼잡제어의 매커니즘
|
네트워크 도움을 통한 방식(network assisted) |
|
|
|
||
|
||
|
종단(end-to-end) 호스트 간 방식 (TCP의 방식) |
네트워크의 도움 없음 |
|
|
송신 호스트가 전송한 데이터에 대한 수신 호스트의 확인응답 유무 혹은 지연을 통하여 네트워크 상태 파악 |
||
|
송신 호스트가 전송률을 제어 |
III. TCP 혼잡제어
가. 혼잡제어 흐름
- 종단간 호스트 사이에 이루어짐
- 소스 호스트는 패킷 전송을 시작하면서 동시에 타이머 동작
- 타임아웃될 때 까지 확인응답 신호인 Ack를 받지 못하는 경우에 전송된 패킷의 손실로 인식하여 재전송
- 특성 상 소스 호스트는 기본적으로 많은 데이터를 빠르게 전송하기를 원함
- 신뢰성 있는 전송을 하는 TCP 프로토콜은 네트워크 상황을 알지 못하고 많은 데이터를 한꺼번에 보낼 수 없으므로 처음에는 적은 데이터를 보냄
- 이에 대한 확인응답 신호를 수신하게 되면 네트워크 상태가 좋은 것으로 생각하여 점차 전송 데이터의 양 증가
나. 혼잡제어 알고리즘
|
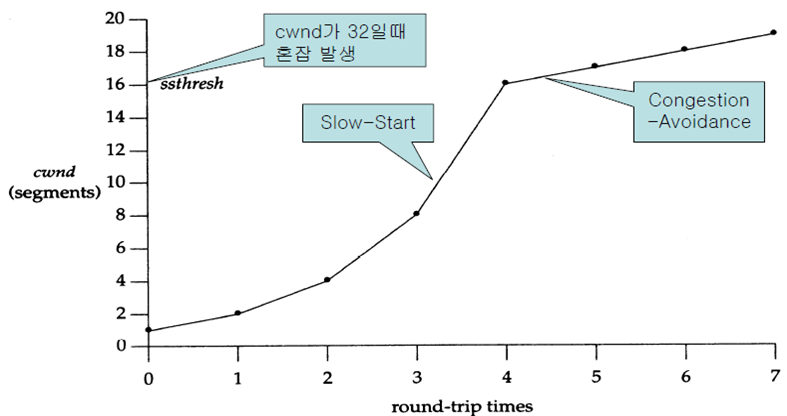
1) 슬로우 스타트(Slow Start) 단계 |
(1) 초기 혼잡윈도우 크기 1로 전송 = 전송 호스트는 하나의 패킷만 전송 (2) 수신 호스트로부터 수신응답을 수신하면 윈도우의 크기를 2로 하여 전송 (3) 수신 호스트로부터 수신응답을 수신하면 윈도우의 크기 4로 하여 전송 (4) 수신 호스트로부터 수신응답을 수신하면 윈도우의 크기 8로 하여 전송 |
|
|
|
2) 혼잡회피(Congestion Avoidance) 단계 |
- 타임아웃의 발생 - 네트워크에 혼잡이 발생하였다고 인식 |
|
혼잡상태로 인식된 경우 - 윈도우의 크기를, 즉 세그먼트의 수를 1로 줄임 - 동시에 임계 값을 패킷 손실이 발생하였을 때의 윈도우 크기의 반으로 줄임 |
IV. TCP Reno
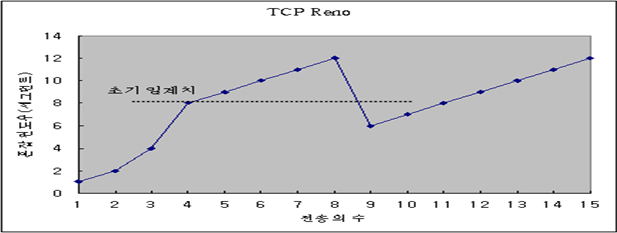
가. TCP Reno 개념
- 빠른 재전송(fast retransmission)과 빠른 회복(fast recovery) 사용
나. 초기 TCP 버전
- 패킷의 손실 발생 여부를 타임아웃을 통하여 알 수 있음
- 타임아웃의 값: 측정된 RTT 값에 안전 여유 값(safety margin) 더한 값
- 실제로 패킷손실이 발생하였을 경우에 재전송하는 반응이 늦게 됨
=> 전송 효율 낮음
다. TCP의 전송효율 높이는 방법
- 가능한 한 혼잡발생 여부 빨리 인식하여 빠른 데이터의 전송 지원
- 혼잡 해결 위해 전송 데이터의 크기 급격히 줄이는 것이 가장 좋음
라. TCP의 중복된 Ack를 사용하는 방법
- 손실된 패킷에 대한 3 개의 연속된 중복 Ack를 수신하는 경우에, 패킷 손실로 생각
- 빠르게 손실된 세그먼트를 재전송함으로 전송 효율을 높일 수 있음
- 패킷 손실이 발생하면, 다음 전송에서 혼잡 윈도우의 크기를 1로 하지 않음
마. 다음 윈도우 크기 조정
- 손실 발생 시 윈도우 크기의 반
- 패킷 손실 직전의 윈도우 크기까지 도달하는 시간이 줄게됨
바. TCP Reno의 알고리즘
|
1) 빠른 재전송(fast retransmission) |
|
|
2) 빠른 회복(fast recovery) |
|
사. TCP Reno에서의 윈도우 크기 변화
 |