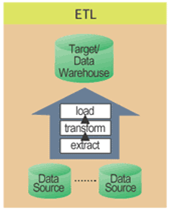
ETT
태그 :
- 개념
- - 데이터를 소스 시스템에서 추출하여 정제/변환 후 DW에 적재 작업까지의 전 과정 - DW 아키텍처 구성 요소간의 데이터 일관성과 통합성을 유지시키는 역할 수행 - ETL(Extraction, Transformation, Loading)이라고도 함 - DW 구축 노력(기간, 인력, 비용)의 80% 이상을 차지 - ETT 의 방법은 소스시스템의 종류, 데이터의 추출주기, 데이터의 양, 로드 속도, 소스데이터의 질, 과거 데이터의 형식, 사용자의 요구조건, 소스시스템의 역할 등에 따라서 달라짐
I. DW의 지속적 사용성 보장, ETT 의 개요
가. ETT(Extraction, Transformation, Transportation)의 개념
- 데이터를 소스 시스템에서 추출하여 정제/변환 후 DW에 적재 작업까지의 전 과정
- DW 아키텍처 구성 요소간의 데이터 일관성과 통합성을 유지시키는 역할 수행
- ETL(Extraction, Transformation, Loading)이라고도 함
- DW 구축 노력(기간, 인력, 비용)의 80% 이상을 차지
- ETT 의 방법은 소스시스템의 종류, 데이터의 추출주기, 데이터의 양, 로드 속도, 소스데이터의 질, 과거 데이터의 형식, 사용자의 요구조건, 소스시스템의 역할 등에 따라서 달라짐
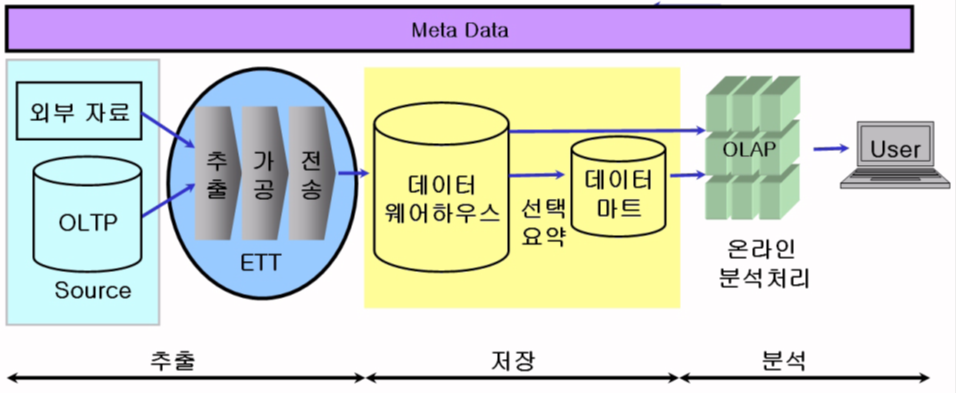
나. 데이터의 추출(Extraction), 가공(Transformation), 전송(Transportation) 의미
|
구분 |
의미 |
|
데이터의 추출 (Extraction) |
- 원본 파일과 트랜잭션 데이터베이스로부터 DW 에 저장될 데이터를 추출하는 과정 임. - 초기 추출은 DW에 처음 데이터를 입력할 때 사용됨. - 주기적 추출은 DW 가 가동된 후 일 단위 또는 월 단위의 주기적인 유지보수에 사용됨. - 주기적 추출의 일반적인 방법은 데이터베이스 로그 파일에서 최근 변화를 기록한 사후 이미지 (After Images)를 추출 |
|
데이터의 가공(Transformation) |
- 질적으로 문제가 있는 데이터를 데이터 정제(Cleansing) 기법을 통해 수정한 후에 사용 - 데이터의 품질을 높일 수 있는 가장 핵심적인 단계 - 필드 수준의 가공과 레코드 수준의 가공이 존재 - 필드 수준의 가공은 원본 필드의 형태를 DW 의 형태에 맞게 변형하는 것을 의미 - 레코드 수준의 가공은 선택(Selection), 결합(Join), 집단화(Aggregation) 기능을 이용하여 레코드 집합을 조작 |
|
데이터의 전송 (Transportation) |
- 선택된 데이터를 DW 에 전송하여 저장하고, 필요한 색인을 만드는 것 - 전체 갱신 방법과 부분 갱신 방법 - DW 의 색인을 만들기 위해 비트맵 색인(Bitmapped Index) 방식을 사용 |
II. ETT 작업 절차
가. ETT의 작업 절차 개념도
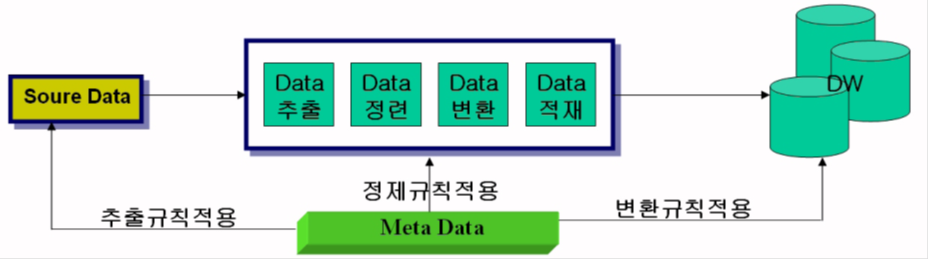
나. ETT의 처리단계 설명
|
ETT 의 기능 |
설명 |
|
데이터 확인 |
- 소스 데이터에서 어떤 데이터를 추출할지 확인 - 유사한 여러 필드가 있는 경우에는 그 중 가장 신뢰할 만 하거나 기준으로 삼을 필드를 정함 |
|
데이터 추출 |
- 실제로 소스 데이터에서 필요한 데이터를 추출함 |
|
데이터 정제 |
- 데이터 품질을 높이기 위한 작업 - 겹치는 필드를 조정하고, 오류의 가능성이 있는 데이터를 기준 데이터나 비즈니스 규칙에 의거하여 정리 |
|
데이터 변환 |
- 추출되고 정리된 데이터를 타겟 데이터 형식에 맞게 변환 - 비즈니스적인 의미를 부여하기 위한 메타데이터 정의/정리 작업 등의 표준화 작업 선결 수행 |
|
데이터 통합(전송) |
- 다양한 소스 데이터들을 단일한 데이터로 의미를 가질 수 있도록 통합하여 DW로 통합 적재(전송) |
III. ETT 특징 및 형태
가. ETT 의 특징
- Data Warehouse 구축에 생명 역할
- 사실 테이블과 요약 테이블을 소스 시스템에서 생성
- ETT 는 정확성과 신속성을 명제로 함
- 소스 시스템에서 특정한 데이터가 바뀌면 로그 파일을 만들고, DW 에서 주기적으로 데이터를 가져옴
나. ETT 의 형태
|
구분 |
내용 |
|
Off-Line 방식 |
메일 또는 배달, 소스시스템에서 데이터를 SAM파일로 만들어서 Data Warehouse로 방식 |
|
On-Line 방식 |
소스시스템 DB와 D/W DB를 직접 연결하여 직접 로딩 방식 |
|
Semi-Online 방식 |
처리계 시스템내에 사용자 로그를 만들어 Data Warehouse 서버가 이 로그 파일을 주기적으로 읽어 가져오는 방식 |
IV. ETT 아키텍처
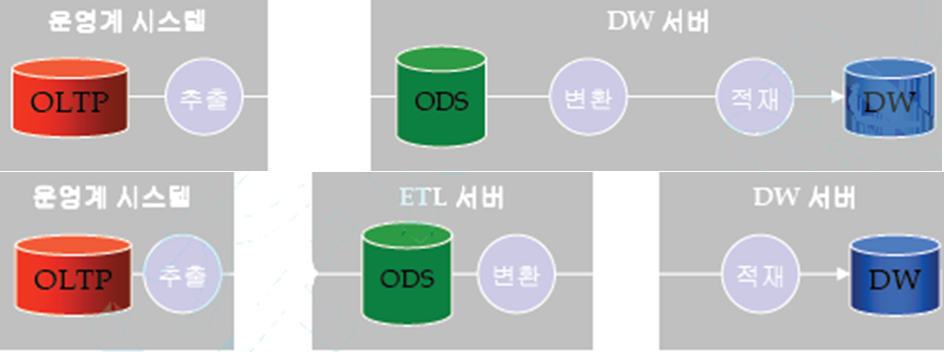
가. 운영시스템 중심
- 운영시스템에 부하를 주는 단점이 있으므로 운영 시스템에 대한 충분한 batch 작업 시간이 확보 가능한지 확인하여야 함.
- 운영계 시스템과 DW 서버간에 꼭 필요한 데이터만 전송되므로 네트워크 부하를 줄일 수 있는 장점이 있음.
- DW 서버에 대한 부하를 최소화하는 아키텍처이므로 다수의 운영시스템으로부터의 통합을 필요로 하는 경우 DW 서버에서의 병목 현상을 최소화할 수 있음.

나. DW 서버 중심
- 운영시스템에 대한 부하가 크고 운영시스템에서 충분한 batch 작업 시간 확보가 어려운 경우(예 : 24 시간 운영되는 웹사이트) 가능한 아키텍처임.
- 운영시스템에서 거의 처리되지 않은 데이터가 DW 서버로 전송되어야 하므로 네트워크 부하가 있을 수 있음.
- DW 서버에 대한 부하가 크므로 다수의 운영시스템으로부터의 통합을 필요로 하는 경우 DW 서버에 대한 충분한 batch 작업시간이 확보되어야 함.

다. 별도 ETL 서버중심
- 운영시스템에 대한 부하와 DW 서버에 대한 부하를 최소화하는 아키텍처임.
- ETL 을 위한 별도의 서버를 구입해야 하는 부담이 있음.
- 다수의 운영시스템과 다수의 데이터 마트가 있는 경우 ETL 도구를 다수의 서버에 설치할 필요가 없음.
V. EII와 ETT의 비교(기출문제)
가. 데이터통합 기술 EII 와 ETL의 개념
|
용어 |
기 본 개 념 |
핵심 |
|
EII |
- 데이터의 원위치를 유지한 상태로 통합하고 필요에 따라 데이터에 접근하는 데이터 통합의 한 형태를 의미 - 데이터 페더레이션 또는 EII 테크닉은 다이내믹한 성격을 가지며 대량의 데이터 접근 또는 다수 시스템의 동시 접근이 필요하지 않은 환경에서 잠재적인 문제를 해결하기 위한 방법으로 활용됨 |
원위치 유지 |
|
ETL |
- 기존의 다양한 시스템과 파일에 저장된 데이터를 하나의 데이 웨어하우스로 통합하기 위해 데이터를 추출,가공, 전송하는 일련의 과정을 통칭 |
추출,가공,전송 |
나. EII와 ETL 비교
|
용어 |
EII |
ETL |
|
개념도 |
|
|
|
데이터 저장소 |
- 데이터 저장공간 (Virtual Data Store) |
- 실질적인 저장공간 확보 |
|
접근 |
- 물리적인 저장소 상관없이 하나의 데이터베이스처럼 접근 |
- 한군데 집약된 데이터베이스에 접근 |
|
데이터 형식 |
- 정형/비정형 모두 사용가능 |
- 정형 타입 사용가능 |
|
데이터 수정 |
- 원천데이터 수정 가능(양방향) |
- 원천데이터 수정 불가능(단방향, Read Only) |
|
데이터 특징 |
- 실시간(Real Time) 접근가능 |
- 배치(Batch) 접근가능 |
|
핵심기술 |
- 데이터 페더레이션 기술 : Connectivity, Federated and Distributed Query Engine, Cache, Consumption, Metadata Repository로 구성되며, 이 중에서 Federated and Distributed Query Engine이 솔루션의 핵심 - Federated and Distributed Query Engine 계층 : EII 기술의 핵심 영역으로서 쿼리를 분해하여 원천 소스에 서브 쿼리를 수행하는 역할을 수행하고 각각의 쿼리 결과는 메모리에 저장되며, 여기에서 조인이나 매핑 작업을 통해 전체 뷰가 만들어짐 |
- 데이터 추출기술 : 원본 파일과 트랜잭션 데이터베이스로부터 데이 웨어하우스에 저장될 데이터를 추출 하는 과정 - 데이터 변환기술 : 질적으로 문제가 있는 데이터를 데이터 정제 (Cleansing) 기술 - 데이터 적재기술 : 선택된 데이터를 데이터웨어하우스에 전송하여 저장하고, 필요한 색인생성 |