데이터마이닝-분류
태그 :
- 개념
- 데이터마이닝 분류기법의 정의 - 다수의 속성(attribute) 또는 변수를 갖는 객체(object)를 사전에 정해진 그룹 또는 범주(class, category) 중의 하나로 분류하는 것
I. 데이터마이닝 분류 기법의 개요
가. 데이터마이닝 분류기법의 정의
- 다수의 속성(attribute) 또는 변수를 갖는 객체(object)를 사전에 정해진 그룹 또는 범주(class, category) 중의 하나로 분류하는 것
나. 데이터마이닝 분류기법의 특징
- 동일 분류에 동일한 예측, 동일한 대응을 함으로써 새로운 상황을 분류한 후 예비대응 조치가 가능
다. 분류를 위한 방법론
|
구분 |
설명 |
|
통계적 방법 |
로지스틱 회귀분석, 판별분석 등 다변량 통계이론에 바탕을 둔 방법 |
|
트리기반 기법 |
CART, C4.5/C5.0, CHAID 등 트리 형태의 분지방법을 이용하는 기법 |
|
비선형최적화 기법 |
서포트백터 머신(Support vector machine: SVM) 등 |
|
기계학습기법 |
신경망 등의 블랙박스 형태의 기법 |
|
구분 기준 |
모형화 |
내용 |
적용기법 |
|
활용 목적 |
서술적 모형화 방법 (Descriptive modeling) |
주어진 데이터를 설명하는 패턴을 찾아내는 것이 주목적 |
연관규칙발견(Association Rule), 군집화(Clustering), Database, Segmentation, Visualization 등 |
|
예측 모형화 (Predictive modeling) |
주어진 데이터에 근거한 모형을 만들고 이 모형을 이용하여 새로운 입력자료들에 대한 예측을 목적으로 함 |
분류(classification) 값예측(Regression, Time series analysis) |
|
|
목표변수 유무 |
Supervised Data |
결과변수(Target)가 정해진 경우 |
의사결정나무(Decision Tree) 인공신경망(Neural Network) 사례기반 추론(Cas-Based Reasoning) |
|
Unsupervised Data |
결과변수(Target)를 가지고 있지는 않음 입력 변수들을 중심으로 데이터사이의 연관성이나 유사성 분석 |
연관성 규칙발견(Association Rule Discovery, Market Basket) 군집분석 (k-Means Clustering) |
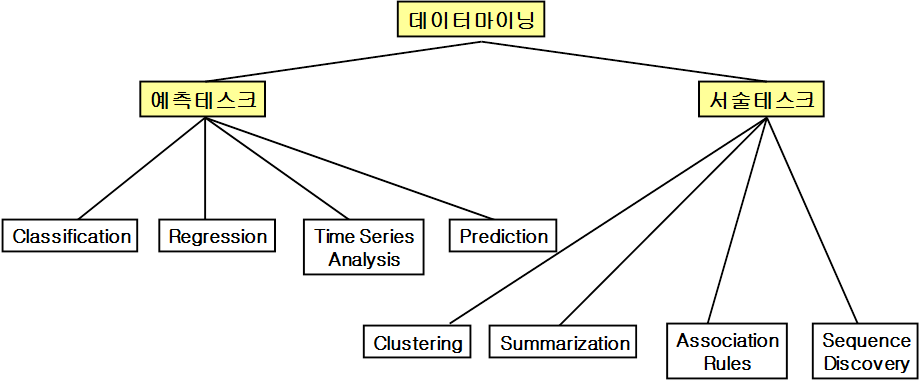
II. 대표적인 분류기법
가. 로지스틱 회귀분석(Logistic Regression)
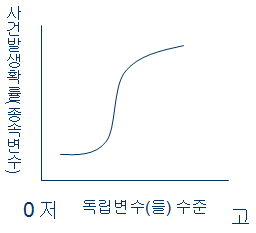
- 정의: 독립변수의 선형결합을 이용하여 사건의 발생가능성(발생확률)을 예측하는데 사용되는 통계기법
- 특징: 독립변수의 선형결합으로 종속변수를 설명한다는 관점에서는 회귀분석, 판별분석과 유사함
- 가정: 종속변수는 명목척도로서 binary data이어야 함
- 분석 과정
- 직접적인 0과 1을 종속변수로 놓는 것이 아니라, 성공할 확률(즉 1이 될 확률) P를 상정
- 로지스틱 분석에서는 이것의 승산비(odds ratio)인 P/(1-P)를 로그를 취해서 이것을 종속변수로 사용
- 종속변수인 P는 직접적인 독립변수가 아니므로, 최대우도비분석 (Maximum Likelihood)을 가지고 계산
- 독립변수와 종속변수 관계에 대한 가정

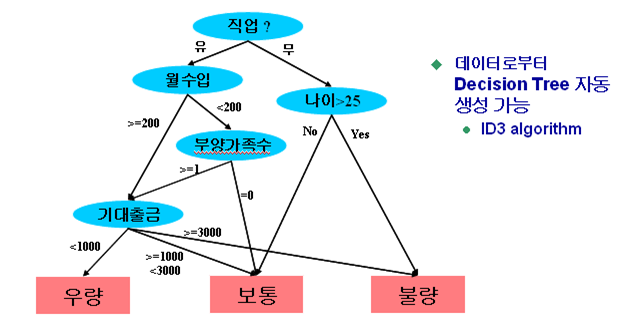
나. 의사결정 트리(Decision Tree) 분석
- 정의: 의사결정 규칙 (Decision Tree)을 도표화하여 관심대상이 되는 집단을 몇 개의 소집단으로 분류(Classification)하거나 예측(Prediction)을 수행하는 계량적 분석 방법
- 특징: 결정트리를 통한 데이터 분석의 결과는 나무(Tree) 구조로 표현되기 때문에 분석가가 결과를 쉽게 이해하고 설명할 수 있음
- 의사결정트리 알고리즘 종류
|
유형 |
내용 |
|
CHAID |
가장 널리 사용되는 알고리즘으로 명목형, 순서형, 연속형 등 모든 종류의 목표변수와 분류변수에 적용이 가능 |
|
CART |
CHAID와 마찬 가지로 목표변수나 분류변수의 척도에 관계없이 적용할 수 있다는 장점으로 인해 널리 사용됨 |
|
C5.0 |
ID3라는 이름의 알고리즘으로 만들어 졌다가 1993년에 C4.5를 거쳐 1998년에 완성된 알고리즘으로 명목형 목표변수만을 지원하는 단점이 있는 반면에 가장 정확한 분류를 만들어 주는 알고리즘으로 평가됨 |
- 분석과정
- 목표변수와 관계가 있는 설명변수들의 선택
- 분석목적과 자료의 구조에 따라 적절한 분리기준과 정지규칙을 정하여 의사결정 나무의 구조 작성
- 부적절한 나뭇가지는 제거 (가지치기)
- 이익(Gain), 위험(Risk), 비용(Cost) 등을 고려하여 모형평가
- 분류(Classification) 및 예측(Prediction)
- 분석결과 예시

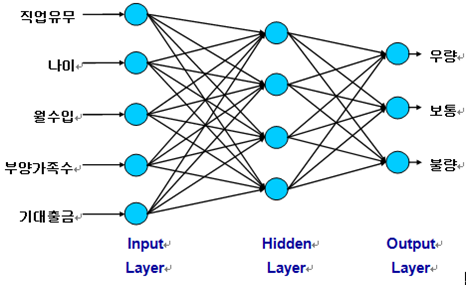
다. 신경망(Neural Network) 분석
- 정의: 인간의 두뇌 자체를 모델로 하여 결정론적 이진 계산 모델에 기반해서 디지털 정보를 처리하는 방식이 아니고, 신경 세포들의 네트워크라는 생각에 기반하여 문제를 고도로병렬적분산적확률적인 계산으로 처리하는 분석방법
- 특징:
- 시간적이고 공간적인 연결강도에 의해서 특정한 장소가 아니라 신경망 내의 연결강도에 의해 정보를 분산적으로 저장
- 새로운 이미지나 패턴 또는 사례가 주어졌을 경우 이를 기억하기 위해 자동적으로 자신의 내부 상태를 변화시킴
- 스스로 학습하는 기능을 가지고 있어 외부입력에 따라서 같은 입력을 주었을 경우에도 서롤 다른 출력이 나올 수 있음
- 신경망 분석의 장점
- 다각도의 문제점 처리에 용이
- 복잡한 도메인 자료에서도 좋은 결과 도출 가능
- 연속형과 범주형 자료 모두 처리 가능
- 분석결과 예시