빅데이터
태그 :
- 개념
- 1) 시스템, 서비스, 조직(회사) 등에서 주어진 비용, 시간 내에 처리 가능한 데이터 범위를 넘어서는 수십 PB 크기의 비정형 데이터 2) 멀티미디어, SNS, RFID, 센서네트워크, 소셜 데이터, 전자상거래, 천문/대기, 의료정보 관련 등 폭발적인 데이터 생산 3) 급격히 늘어나는 데이터 속에서 필요한 정보를 식별 의사결정에 활용 (기존의 분석체계로 불가)
I. 기업의 차세대 생존전략 빅 데이터(Big Data)의 개요
가. 빅 데이터(Big Data)의 정의
1) 시스템, 서비스, 조직(회사) 등에서 주어진 비용, 시간 내에 처리 가능한 데이터 범위를 넘어서는 수십 PB 크기의 비정형 데이터
2) 멀티미디어, SNS, RFID, 센서네트워크, 소셜 데이터, 전자상거래, 천문/대기, 의료정보 관련 등 폭발적인 데이터 생산
3) 급격히 늘어나는 데이터 속에서 필요한 정보를 식별 의사결정에 활용 (기존의 분석체계로 불가)
나. 빅 데이터의 중요성
1) 데이터 급증 : DBMS의 처리 속도, 성능 한계 발생
2) 데이터 가공 : 데이터 홍수 속 정보 활용 가능한 데이터의 추출 요구
3) 신기술 적용 : 통신 융합 미래 지향적인 기술과 시스템간 적절한 연계 필요
다. 빅 데이터와 기존 데이터(경영정보)와의 비교
|
구분 |
빅 데이터 |
기존 데이터 |
|
Volume |
- 수십 PB [페타바이트] |
- 수십 GB, TB |
|
Velocity |
- 실시간 처리 기반(Real Time) |
- 적합한 시간 내 처리 (Right Time) |
|
Various |
- Legacy 데이터 및 트랜잭션 - 모바일, 소셜 데이터, 각종 로그 |
- 기업 내부 발생 데이터 위주 - ERP, CRM, SCM 등 Legacy 데이터 |
|
Device |
- On/Off Line 데이터 포함 - Transaction 및 로그 데이터포함 |
- On-line 데이터 기반 - Transaction Data 기반 |
II. 빅 데이터 아키텍처 구성 및 기술요소
가. 빅 데이터 아키텍처 구성


- Big data 가용성 제고를 위해 데이터 처리 최적화된 기술 요소로 구성됨
나. 빅 데이터 기술 구성 요소
|
구성요소 |
|
|
|
Front End |
경량 script 언어
|
-GC 성능 및 UI구현 이용하고 스크립트언어로 Front End 구성 - Ruby on Rails, Scala, JavaScript, python, PHP |
|
경량App Server |
-다수의 경량Application Server를 이용하여 사용자 응답성의 극대화 -Apache Thrift, Apache Avro, Jetty, Tomcat, nginX |
|
|
Front (Page) Cache
|
-정적리소스 및 동적데이터에 대한 캐시서비스로 App/DB 서버부하절감 및 응답성 향상 -Varnish cache, squid cache, Apache traffic server |
|
|
Middle Tier
|
캐시Pool
|
-DBMS를 통해 빈번하게 조회된 데이터를 메모리에 캐시하여 DB부하 절감 및 응답속도 향상 -Memcached, Membase(CouchBase), Ehcache, Oracle Coherence |
|
분산 미들웨어 |
-분산Application 서버와 Database간의 투명성과 Fault-tolerant를 제공하는 분산메시지기반 미들웨어 -Kestrel(twitter), Kafka(LinkedIn), Apache ActiveMQ, ZeroMQ |
|
|
Back End
|
분산 파일시스템
|
-분산Application 서버와 분산Database를 수평적으로 확장 가능한 네트워크기반의 분산파일 -GFS(Google), Apache HDFS, GLORY-FS(ETRI), OwFS(Naver) |
|
분산 데이터 스토리지/ 연산처리 |
-관계형 DB의 한계를 극복하고 초고용량 데이터의 처리를 위해 새롭게 고안된 데이터 저장방식 -기본적으로 데이터의 분산관리를 지원하며 인덱스의 최적화에 집중화된 DB로 데이터 쓰기가 많은 업무의 실시간 데이터 처리에 최적화된 DB -HadoopMap/Reduce, HBase, MongoDB, cassandra, cloudata, MySqlCluster(InnoDB) |
|
|
DW & 검색엔진 |
-확장 가능한고 성능정보 검색서비스용 라이브러리엔진 및 DW 엔진 -Apache Lucene, Sphinx, Apache Hive |
|
|
System Mgmt |
시스템관리/ 모니터링/분석도구 |
-시스템로그, 성능, 응답성 등을 분석하고 표현하여 신속한 문제파악과 주요지표관리를 통해 운영 조직의 대응 (아키텍처Renewal) 여부와 시점에 대한의사결정지원, 사용자의 서비스 불만 발생 전에 proactive한 대응이 가능. -Apache Zookeeper, Apache Chukwa, Scribe(FaceBook), Jconsole, Java Melody |
|
최적화도구 |
-CPU, 메모리 사용량에 대한 Profiling과 분석을 지원하는 S/W도구를 사용, 극한의 성능구현 -yourkit |
|
III. 빅 데이터의 기술 요인 및 분석 기술
가. 빅 데이터(Big Data) 의 기술요인
|
기술요인 |
설명 |
|
기술적 스킬 |
- 전통적인 데이터베이스와 아키텍처로 처리할 수 없는 대용량의 데이터 세트를 처리 및 발굴, 분석하기 위해 필요한 새로운 차원의 기술 - In-memory, Hadoop(하듑), MapReduce, Key Value Stores 등 |
|
새로운 유형의 비즈니스 분석가/통계전문가 |
- 완전히 새로운 변수와 분석 모델이 요구되는 비정형 데이터가 많고, 이러한 새로운 데이터 유형과 구조에 필요한 분석에서 요구됨. - 데이터 과학, 데이터 과학자 |
나. 빅 데이터(Big Data)의 분석 기술
|
분석 기술 |
설명 |
|
하둡 : Hadoop |
- 분산 시스템 상에서 대용량 데이터 처리 분석을 지원하는 오픈 소스(OSS : Open Source Software) - 소프트웨어 프레임워크, 구글이 개발한 MapReduce를 오픈소스로 구현한 결과물, 월래 야휴에서 최초 개발되었으며 지금은 Apache Software 재단의 한 프로젝트로 관리되고 있음 |
|
구글 파일시스템 (GFS:Google File System) |
- 구글에서 개발한 분산 파일 시스템, Hadoop과 관련되어 있음 |
|
MapReduce |
- 분산 시스템 상에서 대용량 데이터 세트를 처리하기 위해서 구글이 소개한 소프트웨어 프레임워크, Hadoop에도 구현되어 있음 |
|
비관계형 데이터베이스 / Key Value Store |
- 비관계형 데이터베이스는 데이터를 테이블(행, 컬럼)에 저장하지 않는 데이터베이스이며 관계형 데이터베이스와 대조되는 개념임 - Key Value Store를 사용하면 스키마 없는 엔티티(NoSQL)를 관리할 수 있음 |
IV. 빅데이터 분석 진화 모델
|
단계 영향 |
이전 세계 |
새로운 시대 |
||
|
파일럿 |
부서별 분석 |
엔터프라이즈 분석 |
빅 데이터 분석 |
|
|
직원 스킬(IT) |
분석에 전문성이 거의 없거나 전혀 없음 - BI틀에 대한 기초적 지식 |
성능, 가용성 및 보안에 초점을 맞춘 데이터 웨어하우스 팀 |
고급 데이터 모델러 및 관리자가 IT 부서에서 핵심 역할 담당 |
‘데이터 과학자’가 포함된 Business Analytics Comeptency Center (BACC) |
|
직원 스킬 (비즈니스/IT) |
BI 툴에 대한 기능적 지식 |
극소수의 비즈니스 분석가 – 고급 분석을 제한적으로 사용 |
유능한 분석 모델러 및 통계 전문가가 활용됨 |
BACC에 복잡한 문제 해결 기능이 통합됨 |
|
기술 및 툴 |
단순한 시기별 BI 리포팅 및 대시보드 |
데이터 웨어하우스 도입, BI 툴의 광범위한 활용, 제한된 분석용 데이터 마트 |
데이터베이스 내 마이닝, 병렬 처리 및 분석 어플라이언스의 제한적 사용 |
다중 워크로드를 위한 어플라이언스의 광범위한 채택. 새로운 기술을 위한 아키텍처 및 거버넌스 |
|
제정적 영향 |
재정에 큰 영향 없음, 정착된 ROI 모델 없음 |
ROI를 명확하게 이해하며 특정 매출 생성 KPI가 정착되어 있음 |
매출이 큰 영향을 미침 (주기적으로 측정되고 모니터링됨) |
비즈니스 전략 및 경쟁력 차별화 전략이 분석을 기반으로 하고 있음 |
|
데이터 거버넌스 |
없거나 거의 없음 (Skumk 작업) |
초기 데이터 웨어하우스 모델 및 아키텍처 |
표준화된 데이터 정의 및 모델 |
명확한 마스터 데이터 관리 전략 |
|
사업부서(LOB) |
불만 |
가능성 보임 |
연계 및 협력 (사업부서 임원진 포함) |
전사적 참여 (CEO 포함) |
|
CIO 참여 |
드러나지 않음 |
제한됨 |
참여함 |
혁신적임 |
V. 데이터의 효율적인 관리를 위한 필요 기술 및 생명주기별 기술
가. 빅 데이터의 효율적인 관리를 위한 필요 기술
|
기술 구분 |
설명 |
필요 기술 |
|
원본 데이터 저장 |
- 대용량 분산 파일 저장 - 로그 기반 데이터 포함 |
- Hadoop File System - MapReduce |
|
구조적 데이터 저장 |
- 대용량 분산 데이터 저장소 - DBMS의 처리 한계 대체 기술 |
- NoSQL, HBase -Cassandra, MongoDB |
|
배치 분산 병렬 처리 |
- 분산 데이터 처리 기술 - 결과 그래프 분석 기술 |
-MapReduce (Hadoop) - Pregel, GlodenORB |
|
데이터 스트리밍 프로세싱 |
- 스트리밍 데이터 프로세싱 기술 |
- Streaming DBMS - DW Appliance |
|
데이터 마이닝 |
- 빅 데이터의 패턴 분석 및 고객 분석을 위한 알고리즘 |
- 군집화, 분류화 - 기계학습(Neural Net) |
|
데이터 분석 알고리즘 |
- 데이터 분석을 위한 세부 기술 - Social Network Anaylsys |
- Clique 분석 - Centrality 분석 |
|
분산처리 기술 |
- 관리 기술, 분산 큐 기술 -분산 캐시 기능 |
- ZooKeeper, kafka - Memcached, Redis |
- 빅 데이터의 효율적인 관리를 위해 분산처리 기반의 기술과 기존의 데이터 분석 기술을 활용하며 실시간 분석을 위한 인프라 정비가 필요함
나. 빅 데이터의 Life-Cycle별 기술 설명
|
필요 기술 |
설명 |
|
|
데이터 수집 |
Open API/ OAuth |
- SNS에서 제공되는 빅 데이터 Feeding을 위한 표준 API - 개방형 인증체계 |
|
오픈 플랫폼 |
- SNS 등에서 생성되는 데이터를 제공하는 소셜 기반의 플랫폼 |
|
|
Hadoop |
- 대용량, 비정형 데이터를 분산처리하기 위한 개방형 표준 아키텍처 |
|
|
MapReduce |
- Map(), Reduce() 연산을 통한 대규모 분산 병렬처리 기법 |
|
|
데이터 분석 |
시멘틱 분석 |
비정형 데이터에 대한 온톨로지 구축 및 데이터 명세화 |
|
관계성 분석 |
데이터간 관계분석 및 Social Rank 체계 구축 |
|
|
감성 분석 |
빅 데이터의 실질적 의미 파악 및 분석 |
|
|
데이터 활용 |
마케팅 |
SNS 등에서 유통되는 데이터 분석, 기업의 브랜드 관리에 활용 |
|
공공서비스 |
민원 텍스트 연관 분석 통한 미원 원인 도출(오피니언 마이닝) |
|
|
비즈니스화 |
빅 데이터를 분석, 2차 가공하여 제3자에게 제공되는 비즈니스 모델 |
|
- 데이터 관리를 위해 효과적인 데이터 분석이 선행 되어야 함.
- 빅 데이터 실시간(Realtime) 분석을 위해 기술 및 관리 부분에서 어려움이 예상됨
다. 빅데이터의 Life-Cycle별 세부기술
|
구분 |
설명 |
세부기술 |
|
데이터 소스 |
- 데이터 소스는 내/외부 데이터를 아우르며 모바일, SNS, 센서 데이터를 포괄함 - 비정형, 반정형, 정형 데이터를 모두 포괄함 |
- M2M 기반 소스, 로그 기반 처리, Legacy 데이터, File, Image, 동영상 등 |
|
수집 |
- 모든 디바이스 및 시스템에서 나오는 데이터를 수집할 수 있는 기술 |
- 웹 로봇, CEP(Complex Event Processing) 등 |
|
저장/처리 |
- 수집된 대용량 데이터를 저장하며 분산처리 시스템에 의 해 처리할 수 있는 기술 |
- 하둡, HBase, 카산드라, NoSQL, 망고DB 등 |
|
분석 |
- 빅 데이터를 이용해 기업에 도움이 될 수 있고, 생활에 도움을 줄 수 있는 분석방법 |
- 데이터 마이닝 알고리즘, 인공지능 기법 등 |
|
표현 |
- 분석된 결과를 효과적으로 표현할 수 있는 기술 |
- R, 그래프, 도면 등 |
VI. 빅 데이터 분석의 문제점, 극복방안 및 활용 사례
가. 빅 데이터 분석의 기술적 문제점과 극복방안
|
빅 데이터 분석의 어려움 |
기술적 극복방안 |
|
- 방대한 비정형 데이터의 폭발적 증가 - 데이터의 수집, 분류, 처리에 대한 어려움 |
- 특정 키워드 기반 필터링 기술활용 - Text Mining, Web Mining 등 기존 기술활용 가능 |
|
- 개인정보를 포함하는 소셜 데이터의 수집 |
- 개인정보를 제외한 내용만 수집하는 방안 마련 |
|
- 불용어, 속어 등에 대한 자연어 처리 이슈 |
- 신경망, 유전자 알고리즘 등을 통한 고도화된 인공지능 기술 연구 - 시멘틱 검색, SNA 분석, 패턴기반 정보분석 기법 활용 |
- 빅 데이터의 성공적인 활용사례 부족에 따른 기업의 어려움이 증가되고 있음
- 이에 따라, 글로벌 기업의 성공적인 빅 데이터 분석에 대한 성공사례, Bench-Marking 필요
나. 빅 데이터 분석의 어려움을 극복한 Best-Practice
|
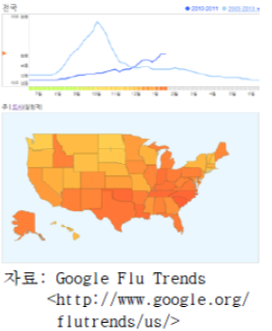
구글의 독감 유행 정보를 감지하는 검색엔진 사례 |
|
|
- 기존에는 특정 국가나 지역을 담당하는 보건기구가 외료기관이 보고하는 정보를 이용하여 독감 감시체계를 운영
- 구글은 독감 증상이 있는 사람들이 늘어나면 관련된 주제를 검색하는 빈도도 함께 늘어난다는 사실을 발견하고, 시간/지역별 검색기반 독감 유행 정보를 Google.org를 통해 제공
- 주 단위로 갱신되는 보건당국의 발표와 달리 구굴의 독감 유행 정보는 매일 갱신되므로 독감 유행 징후를 빠르게 감지하고 대응책을 마련하는 데 유용한 보완 정보로 기능 |
- 구글이 검색통계로 추정한 독감 유행 지수 변화(上)와 미국 각 주별 현황(下)
|
VII. 빅 데이터 분석과 기존 경영정보분석의 차이점
가. 빅 데이터 (Big Data) 분석과 기존 경영 정보 분석과의 차이점
|
요소 |
경영정보(과거) |
Big Data(새로운 시대) |
|
인프라형태 |
- 독립인프라 |
- 리소스 풀 |
|
아키텍처 |
- 최적화 |
- 확장성 (분산 병렬 프로세싱 및 인 메모리(IN-MEMORY) 스토리지와 연계) |
|
딜리버리 모델 |
- 온-프레미스(on-premise) - DW 환경, BI |
- 하이브리드 (클라우드 버스팅 기능 포함) 및 어플라이언스의 일반적인 사용 |
|
데이터세트 |
- 사전 정의됨 |
- 포괄적이고 반복적임 |
|
데이터속도 |
- 배치 |
- 능동적이고 다이나믹 함 (실시간) |
|
데이터분석 |
- 주로 과거 분석 |
- 예측 및 최적화 |
- 빅 데이터 분석과 기존 경영 정보 분석의 차이점은 크게 최적화, 실시간, 예측분석의 가능성으로 볼 수 있음
나. 빅 데이터(Big Data) 분석 전략
|
요소 |
분석전략 |
설명 |
|
인프라형태 |
클라우드 버스팅(Bursting) |
- 프라이빗 클라우드의 미래는 전사적 차원의 비즈니스 분석 요구 사항과 방향성이 같을 것. |
|
아키텍처 |
엔터프라이즈 아키텍처 |
- 조직이 엔터프라이즈 분석을 사용하기 위해 서비즈니스 성장에 맞춰 규모를 확장할 수 있는 체계적인 엔터프라이즈아키텍처 필요, 고사양 분석 환경 |
|
딜리버리모델 |
분석 어플라이언스 Analytics appliance |
- 분석 어플라이언스가 빅데이터를 다루는 데 가장 큰 장점, 최적화를 통한 구축 소요시간 단축 |
|
Data처리(세트/속도/분석) |
빅 데이터 분석 |
- 빅 데이터 분석을 통해 창출되는 잠재적 가치 및 효과 기대, 최적화/실시간/예측분석 |
VIII. 빅 데이터 분석의 활용효과
가. 기업은 빅 데이터의 분석을 통해 경쟁환경을 이해하고 효과적으로 전략을 실행 할 수 있는 기반을 강화

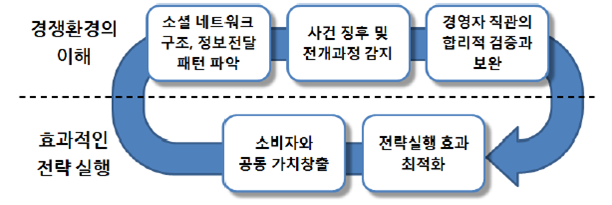
나. 소셜 네트워크의 구조와 정보전달 패턴 파악
1) 소비활동에 영향을 주고 받는 소비자들의 소셜 네트워크 구조를 파악하여 효과적인 마케팅을 위한 기반정보를 확보
2) 소비자들은 기업이 제공하는 정보보다 프로슈머(prosumer), 커뮤니티의 동료등이 제공하는 정보를 더욱 신뢰
3) 소셜미디어에 나타나는 정보의 경로를 분석하면 잠재적 소비자군과 이들이 소속되어 있는 다양한 커뮤니티 구조를 파악하는것이 가능
4) 정보의 발산력이 우수한 오피니언 리더와 커뮤니티와 이들이 활용하는 정보 발산 채널에 마케팅 노력을 집중함으로써 효과를 극대화