하둡
태그 :
- 개념
- - 데이터 처리와 저장소 역할을 하는 여러 컴퓨터에 대용량 데이터를 분산 저장 및 분산 처리 하는 오픈 소스 소프트웨어(OSS) 프레임워크
I. 대규모 분산컴퓨팅환경을 지원하는 프레임워크, Hadoop의 개요
가. Hadoop의 정의
- 데이터 처리와 저장소 역할을 하는 여러 컴퓨터에 대용량 데이터를 분산 저장 및 분산 처리 하는 오픈 소스 소프트웨어(OSS) 프레임워크
나. Hadoop의 등장배경
- 최근 클라우드 컴퓨팅의 대중화로 인한 대용량 데이터의 안정적인 처리 및 관리가 필요
- 클라우드 컴퓨팅을 도입하는 기업들의 비용대비 효과 달성을 위해 클라우드 사업자의 저가 하드웨어와 오픈소스 기반 SW 이용 추세
II. Hadoop의 구성도 및 구성요소
가. Hadoop의 구성도
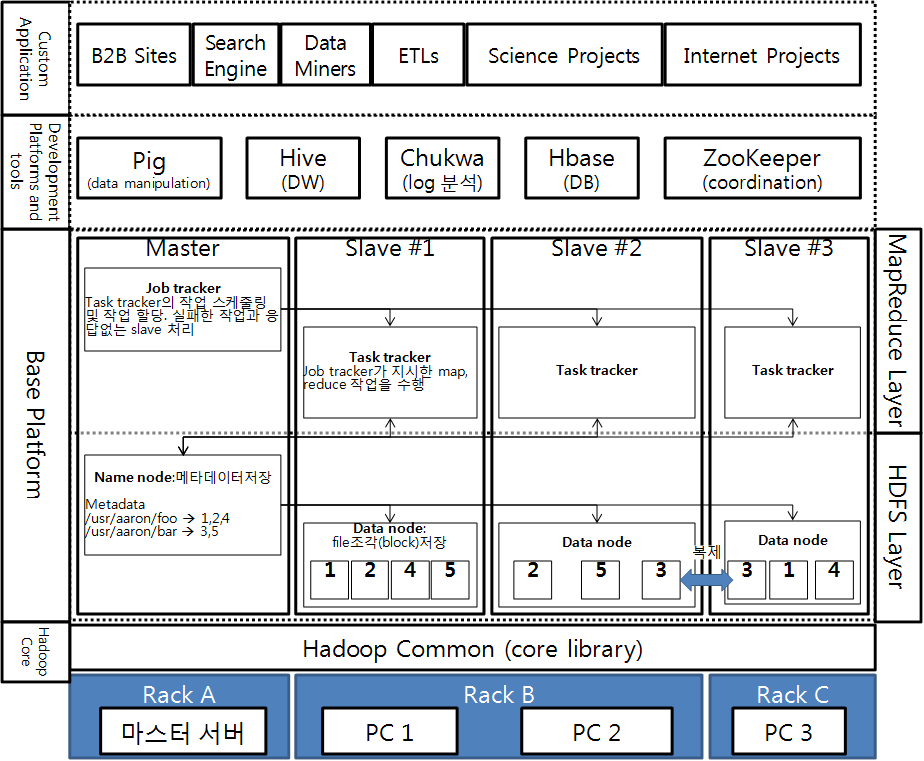
나. Hadoop의 구성요소
|
주요기술 |
설명 |
|
Hadoop Common |
Hadoop 구성요소를 위한 공통 유틸리티 |
|
MapReduce |
대용량 데이터 세트를 처리하거나 생성하기 위한 프로그래밍 모델 Map Phase: 각 데이터를 한줄 씩 읽어서 키와 벨류로 묶어줌. Reduce Phase: Map Phase에서 데이터를 받아 합치고 정리함
|
|
HDFS (Hadoop Distributed File System) |
|
다. Hadoop 관련 주요 프로젝트
|
구분 |
설명 |
|
HBase |
확장가능하고, 분산된 데이터베이스를 Hadoop Core 위에 제공함 |
|
PIG |
대규모 데이터셋을 탐색하기 위한 프레임워크로, 스크립트를 통해서 맵리듀스 기능을 수행하는 환경 제공 |
|
Hive |
HDFS에 저장된 데이터를 관리할 수 있도록 쿼리를 제공하는 데이터 웨어하우스 프로젝트 |
|
Chukwa |
분산 환경에서의 로그 수집 및 저장을 위한 오픈 소스 프로젝트 |
|
Zookeeper |
|
|
Avro |
Data Serialization 시스템 |
|
Cassandra |
Single points of failure가 없는 확장 가능한 multi-master DB |
III. Hadoop의 특징 및 RDBMS와의 차이점
가. Hadoop의 특징
|
특징 |
내용 |
|
Scale-Out |
-장비가 추가될 때마다 전체 가용량(capacity) 및 성능이 거의 선형적으로 증가하는 구조 |
|
노드 변경 용이 |
-JobTracker와 Name node는 다른 장비들과 주기적으로 통신하면서 상태 감시 -일부 장비 제거나 추가시 자동으로 인식하여 처리함 -시스템을 중단하지 않더라도 장비의 추가 및 삭제가 비교적 자유로움 |
|
높은 가용성 |
-일부 장비에 장애가 발생하더라도 전체 시스템 사용성에 영향이 적음 |
|
SPOF구조 |
-Single Point of Failure 구조 -TaskTracker와 Data Node의 장애에 대해서 강건한 반면, JobTracker와 Name Node에 생기는 장애에 대해서 취약한 단점 |
|
Throughput에 최적화 |
대용량 데이터의 배치 처리에는 적합하나, 스트리밍과 같은 실시간성 데이터 분석이나, reduce task의 입력 데이터가 큰 작업에는 효율이 저하됨 |
나. HADOOP과 RDBMS의 비교
|
구분 |
관계형데이터베이스(RDBMS) |
HADOOP (MapReduce) |
|
데이터크기 |
기가바이트 |
페타바이트 |
|
엑세스 |
대화형 일괄처리 |
일괄처리 |
|
업데이트 |
여러 번 읽고, 쓰기 |
한번쓰면 여러 번 읽기 |
|
구조 |
고정스키마 |
동적스키마 |
|
무결성 |
높음 |
낮음 |
|
확장성 |
비선형 |
선형 |
IV. MapReduce의 처리방식
가. 처리방식 구성도

나. 병렬처리 방식 개념도

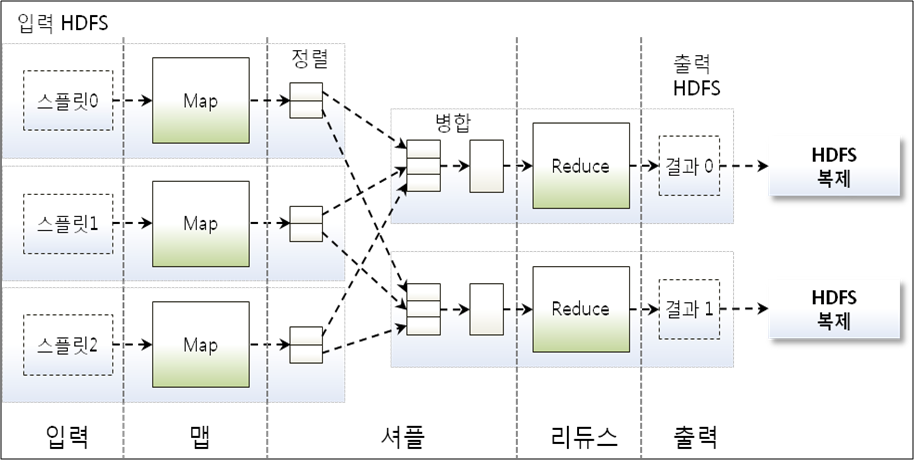
다. 맵 리듀스 체인

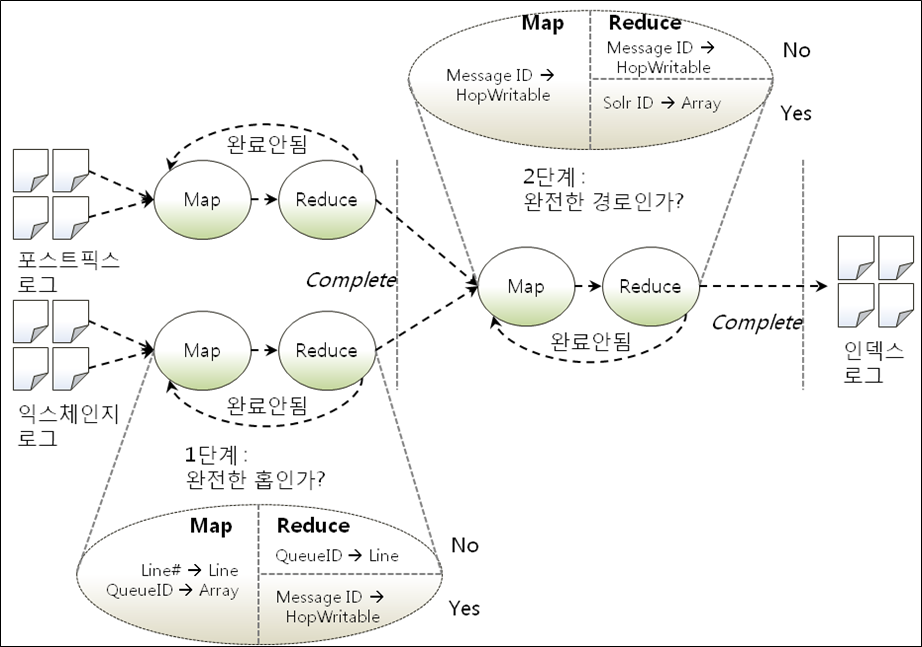
V. Hadoop 적용 분야 및 발전방향
가. Hadoop의 적용분야
|
적용분야 |
설명 |
|
검색 포털 서비스 |
검색엔진으로부터 수집된 데이터를 기반으로 키워드 추출, 인덱스 구축 및 저장 관리에 사용 |
|
통신, 미디어 서비스 |
Call log 와 Service log 데이터를 분석해 유사 관심 고객의 트렌드를 분석한 개인 맞춤형 서비스를 제공 서비스 인프라 자원 효율적 관리 |
|
바이오 인포매틱스 분야 |
염기서열 정렬, 유전체 변이정보 분석, 단백질 구조 모델링을 통한 신약개발 분야에서 활용 |
|
대규모 글로벌 서비스 |
인터넷 서비스 기업, 트위터, 페이스북, 소셜네트워킹 서비스(SNS) 기업에서 사용 중 |
|
기타 |
비즈니스 인텔리전스(BI), 과학계산 등 응용분야로 확산됨 |
나. Hadoop의 발전방향
- map/reduce 단계의 부하 불균형 해소를 위한 작업 스케줄링 방식 개선을 통한 효율 향상
- 여러 노드들 간의 Data 및 제어 명령 전송에 사용되는 네트웍 I/O 부하 개선을 위한 TCP/IP 이외의 통신 프로토콜 적용
- Hadoop 클러스터의 효율적 관리를 위한 전용 모니터링 어플리케이션 개발.
VI. 그린플럼 데이터 컴퓨팅 어플라이언스의 네 가지 모듈
|
구분 |
설명 |
|
그린플럼 데이터베이스 모듈 |
목적별(purpose-built) DW 어플라이언스 모듈로 확장성이 매우 뛰어나다. 데이터베이스, 컴퓨팅, 스토리지 및 네트워크를 쉽게 실행할 수 있는 엔터프라이즈 시스템 |
|
고용량 모듈 |
전원과 설치공간을 추가로 늘릴 필요 없이 수 페타바이트의 데이터를 관리할 수 있도록 설계 매우 방대한 양의 데이터를 정교하게 분석해야 하는 기업이나 장기적인 아카이빙이 필요한 기업들을 위해 단위당 가장 저렴한 비용의 DW를 제공 |
|
HD 모듈 |
고성능 데이터 상호 연계 처리 하둡 어플라이언스 모듈. 하둡과 그린플럼 데이터베이스를 결합시켜 정형 데이터와 비정형 데이터 모두를 단일 솔루션 내에서 상호 연계 처리 |
|
HD 모듈 |
인터넷 서비스 기업, 트위터, 페이스북, 소셜네트워킹 서비스(SNS) 기업에서 사용 중 |
|
통합 가속기 모듈 |
배치 로드를 줄이거나 마이크로 배치 로딩을 실행할 경우 업계 최고의 데이터 로딩 성능을 제공 |