몽고 DB
태그 :
I. 현대 웹을 위한 다큐먼트 데이터베이스, 몽고 DB의 개요
가. 몽고 DB의 핵심 아이디어
- 플랫폼을 위해 개발 : 데이터베이스가 여러대의 서버에 걸쳐 점차로 확장할 수 있어야 한다는 것을 의미함
- 웹 어플리케이션의 데이터 저장 시스템: 일차적 데이터 자정 시스템으로서 수평적으로 확장가능하록 설계 되었음
나. 몽고 DB 를 사용하는 이유
- 용도관점 : 웹 애플리케이션 분석과 로깅 애플리케이셔 중간 정도의 캐시를 필요로 하는 애플리케이션에서 일차 데이터저장 시스템에 적합
- 스키마가 존재하지 않는 데이터를 저장하기에 용이하여 미리 구조가 알려지지 않은 데이터를 저장하는데 유용
다. 몽고 DB의 특징
|
특징 |
설명 |
|
Documented-oriented DB |
컬럼의 명시가 되어있지 않고 하나의 안에 들어가는 내용을 아주 유연하게 (key,value) 담을 수 있는 계층 구조 |
|
Schema-free |
스키마 정의가 필요없다 |
|
Easy Scaling(확장성) |
Auto-sharding 방식을 제공함, 클라우드 환경에서의 확장성 만족 |
|
HA(안전성) |
Master/slave방식 제공, replica-set 방식 제공, auto-sharding 방식과 혼합하여 구성할 경우 band-width, 트래픽 분산의 이점이 있음 |
II. Document-oriented DB, 몽고 DB의 핵심 기능
가. 다큐먼트 데이터 모델
- 도큐먼트 지향적 데이터 베이스임
- 오브젝트의 컬렉션형태로 표현함으로써 객체를 전체적으로 작업함
- 도큐멘트는 미리 정해진 스키마가 없음
- Application 이 데이터 구조를 정함


- 속성의 이름과 값으로 이루어진 쌍의 집합
- 속성값 : 문자열/숫자/날짜와 같이 간단한 데이터타입/배열/다큐먼트도 가능
- 구성요소를 하나의 도큐먼트로 다양한 구조의 데이터로 표현
- 태그/Comment를 배열로 저장 함
[관계형 데이터베이스]

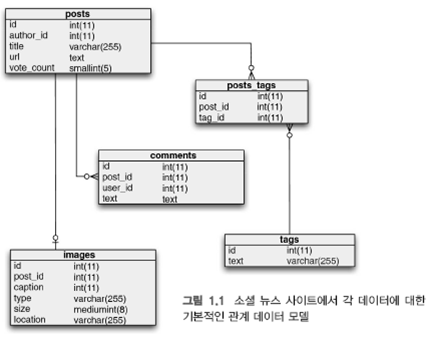
- 정규화, post와 tag의 조인 연산이 필요하고 코멘트를 보여 주기 위해 쿼리수행해야함
나. 애드혹 질의
- 시스템이 받아 들일 수 있는 질의를 미리 정의할 필요가 없다
- 관계데이터베이스의 기본적인 질의 성능을 유지하려고 하는 것이 몽고DB의 설계 목표
|
Posts와 comments관련한 예 추천수가 이상이고 ‘’라는 용어로 태그된 모든 포스트 검색 |
|
[SQL질의어] SELECT * FROM posts INNER JOIN posts_tags ON posts.id = posts_tags.post_id INNER JOIN tags ON posts_tags.tag_id == tags.id WHERE tags.text = 'politics' AND posts.vote_count > 10; |
|
[몽고DB질의어] db.posts.find({'tags': 'politics', 'vote_count': {'$gt': 10}}); |
- 여러 개의 속성을 임의로 조합하여 질의할 수 있는 능력을 보여주고 있음
- 인덱스를 잘 정의하면 퀴리와 정렬 속도가 10배 이상의 단위로 빨라지므로 애드혹 쿼리를 지원하는 시스템은 세컨더리 인덱스를 지원함
다. 세컨더리 인덱스
- B tree로 구현됨
- 한 컬레션에 64개의 세컨더리 컬렉션을 만들 수 있음
- 역순,고유,복합키,지리공간적인덱스가 가능함
- 여러 개의 세컨더리 인덱스를 가지고 질의어를 최적화 할 수 있음
라. 복제
- Replica set이라 부르는 구성을 통해 데이터베이스 복제 기능을 제공
- 서버와 네트워크 장애가 발생할 겨우 대비해 중복성과 자동 장애 조치를위해 데이터를 여러대의 서버에 분산함
- 데이터 읽기에 대한 확장을 위해서 사용
- 웹과 같은 읽기 위주의 애플리케이션에서는 데이터베이스 읽기를 복제셋 클러스터 내의 여러 서버에 분산이 가능함

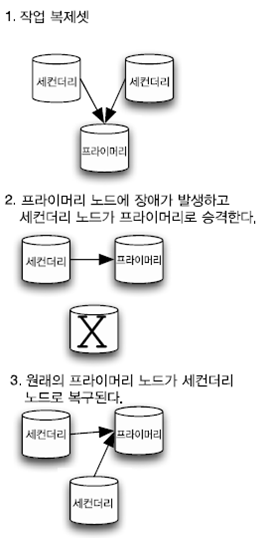
마. 속도와 내구성
- 쓰기 속도 : 미리 정해진 시간내에 데이터베이스가 얼마나 많은 수의 삽입 수정 삭제 명령을 처리할 수 있는가를 의미
- 내구성 : 쓰기 연산이 디스크에 제대로 이루어졌는지 확신할 수 있는 정도
- 쓰기 시맨틱스(write symantics) 와 Jounaling을 통해 속도와 내구성 사이에서 타협할 수 있음
- 모든 쓰기 : 명령하고 잊어버리기 모드(fire-and-forget) –쓰기 연산을 TCP 소켓으로 보내고 나서 그 결과에 대한 응답을 기다리지 않음단위데이터가 작고 발생량은 방대한데이터나로그에 사용
- 안전 모드 : 쓰기 연산에 대한 최소 응답을 기다림, 쓰기 연선이 몇 개의 서버에 중복 될 때 까지블록하는데 사용중요도 높은 데이터
바. 확장
- 수평적 확장(Scaling horizontally) 혹은 외적 확장(Scaling out)을 고려

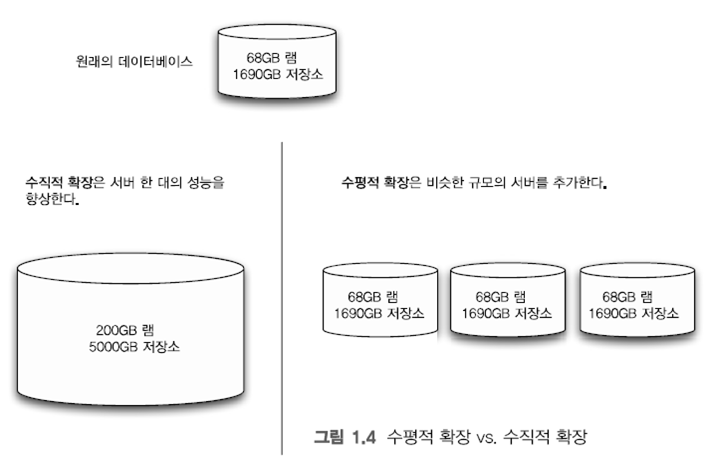
- 수평적 확장 : 단하나의 노들르 업그레이드 하는 대신에 데이터베이스를 여러대의 서버에 분산시키는 것을 의미함
- 몽고 DB는 수평적 확장이 가능하도록 설계 됨
- Auto-Sharding의 파티션 메커니즘을 통해 데이터를 여러 노드에 걸쳐 분산하는 것을 자동으로 관리 해줌
- 어플리케이션은 샤드 클러스터에 연결하여 사용함으로 내부 메커니즘은 신경을 쓰지 않아도됨
III. 몽고 DB와 다른 데이터베이스의 비교 및 사용예
가. 몽고 DB와 다른 데이터베이스의 비교
|
|
예 |
데이터 모델 |
확장 모델 |
용례 |
|
간단한 키-값 저장 시스템
|
멤캐시디 (Memcached) |
키-값, 여기서 밸류는 이진 blob |
여러 가지, memcached는 이용 가능한 램으로 노드에 걸쳐 확장함으로써 하나의 단일한 데이터 스토어로 변환한다 |
캐싱, 웹 ops |
|
정교한 키-값 저장 시스템 |
카산드라, 볼드모트 프로젝트 (Project Voldemort), 리악(Riak) |
여러 가지가 있다. 카산드라는 칼럼(column)으로 부르는 키-값 구조를 사용하고, 볼드모트는 이진 blob을 사용한다. |
높은 확장성과 용이한 쟁애조치를 위한 Eventually-consistent, 다중 노드 분산 |
고효율 verticals (액티비티 피드, 메시지 큐), 캐슁, 웹 oos |
|
관계 데이터베이스 |
오라클, MySQL, PostgreSQL |
테이블 |
수직적 확장, 제한적인 클러스터링과 수동적인 파티션 |
트랜잭션이 필요한 시스템 또는 SQL 정규화된 데이터 모델 |
나. 사용예 와 한계
|
웹어플리케이션 |
일차적 저장 시스템으로 사용하기에 적당 |
|
Agile |
일차적 저장 시스템으로사용하기에 적당 |
|
Agile 개발 |
고정된 스키마가 없어 신속한 개발이 가능함 |
|
분석과 로깅 |
분석에 적합한 속도타깃원자적 업데이트와 캡드 컬랙션이라는 특징 때문에 유용함 |
|
캐싱 |
더 빠른 질의어와 전체적으로 표현할 수 있는 데이터 모델 적용 |
[ 실제 서비스되는 시스템으로 배포하기 전에 한계점]
- 메모리 맵(memory-mapped)파일을 사용한 결과에서 발생한 것임
- 보통 64 비트 시스템에서 실행 되어야 함
- 필요할 경우 메모리 자동 할당 : 공유 환경에서 실행이 어려움
- 복제와 저널링을 사용 : 셧다운 시 데이터가 손상 될 수 있음, 장애 조치를 위해 복제된 백업 서버를 가지고 있어야 함